다음 시간에 웹크롤링과 OpenAPI 사용 실습을 해볼 예정이다.
크롤링은 서울특별시 코로나 19 정보와 코로나 관련 네이버 뉴스에 대해, OpenAPI는 정부 공공데이터 포털과 서울 열린 데이터 광장에 대해 진행할 것이다.
우선 실습을 해보기 전에 무엇인지부터 배웠다.
[Part 1] 웹크롤링
1. 웹이란?
: World Wide Web(WWW)의 줄임말
참고로, 인터넷은 컴퓨터 네트워크 통신망을 의미하고, 웹은 그 인터넷상에서 동작하는 하나의 서비스이다.
1) 웹 브라우저
: 웹을 보기 편하게 해주는 소프트웨어 ex) 엣지, 크롬, 사파리
2) HTTP(Hypter Text Trasfer Protocol)
: 클라이언트와 서버 사이에서 정보를 주고받기(문서 전송) 위한 규약
여기서 클라이언트란 브라우저를 통해 서버에 데이터를 요청하는 컴퓨터이고, 서버란 클라이언트가 데이터를 요청하면 요청에 따라 데이터를 전송하는 컴퓨터이다.

3) Request 형태
| GET 방식 | POST 방식 | |
| 데이터 전달/전송 방식 | URL 내에서 | 태그를 통해서 (사용자에게 직접 노출X) |
| Body | Body가 빈 상태로, Header만 전송 | Body에 query data가 들어감 |
| 특징 | URL에 데이터 포함 → 데이터 노출 | URL을 가지지 않으므로 중요한 데이터를 다룰 때 사용 |
| 링크/북마크 | O 가능 | X 불가능 |
| 예시 | 네이버 검색, 구글 검색 | ID, 비밀번호가 필요한 경우 |
※ Header
: 데이터 앞부분에 파일에 대한 정보를 실어놓은 부분 (브라우저는 header 자동지정)
근데 파이썬은 헤더 정보를 자동으로 담지 않기 때문에, 따로 헤더 지정이 필요하다.
※ Cookie
: HTTP에서 사용자의 정보를 저장하는 데이터 (HTTP 응답 코드를 보낼 때 같이 보내짐)
4) HTTP Staus Code
: 서버와 클라이언트가 데이터를 주고받으면, 주고받은 결과로 상태 코드 확인 가능
| HTTP Staus Code | Status | Detail |
| 2xx | success(성공) | 요청을 성공적으로 받았으며 인식 및 수용 |
| 3xx | redirection(browser cashe) | 요청 완료를 위해 추가 작업 조치 필요 |
| 4xx | request error(클라이언트 오류) | 요청의 문법이 잘못되거나 요청 처리 불가 |
| 5xx | server error(서버 오류) | 서버가 명백히 유효한 요청에 대한 충족 실패 |
예를 들어, 가장 흔히 보이는 404 not found가 request 오류이다.
2. 크롤링(crawling)이란?
여러 웹페이지에 있는 데이터들을 프로그래밍적으로 수집하고 분류하는 작업이다.
· 스크랩핑: 각각의 페이지에서 정보를 추출하여 데이터를 수집하는 작업
· 크롤러: 자동으로 정보추출을 반복하는 프로그램
1) 다양한 크롤링 방법
· HTML 페이지를 가져와서, HTML/CSS 등을 파싱하고, 필요한 데이터만을 추출하는 기법
· Open API(Rest API)를 제공하는 서비스에 Open API를 호출해서, 받은 데이터 중 필요한 데이터만 추출하는 기법
· Selenium 등 브라우저를 프로그래밍으로 조작해서, 필요한 데이터만 추출하는 기법
2) 크롤링 방식의 종류
① urlib
· Python built-in module
· 간편하게 HTTP request를 보낼 수 있음
· 로그인 및 세션 유지가 번거로움
② Requests #doc
· html 문서를 가져올 때 사용하는 패키지
· 사용자 친화적인 문법을 사용하여 다루기 쉬우면서 안정성이 뛰어남
· 세션 유지가 용이
· 간편하게 HTTP request를 보낼 수 있음
· python2 / python3 완벽 지원
· 코드가 간결하고 documentation이 잘 되어 있음
③ Selenium #doc
· 웹 브라우저 자동화 tool
· javascript/CSS 지원, 기존 GUI 브라우저 자동화 라이브러리
· chromedrive를 이용해 크롬을 제어하기 위해 사용
· 사람이 웹서핑하는 것과 동일한 환경, 대신에 리소소를 많이 사용
· 웹 브라우저에서 HTML에 명시된 이미지/CSS/JavaScript를 모두 자동 다운로드 및 적용
④ BeautifulSoup
· 쉽고 간결하며, documentation이 매우 잘 되어 있음
· 정규식을 작성할 필요 없이 tag, id, class 등의 이름으로 쉽게 파싱 가능
크롤링을 정식으로 배워보지 않은 내가 프로젝트를 할 때 사용했던 라이브러리이다. 그만큼 사용하기 편리하다.
| BeautifulSoup | Selenium | |
| 웹 페이지 접속 | HTML 정보 다운로드 후, 브라우저 영향X | 웹 페이지 연결 유지 필요 |
| 웹 페이지 동작 | X 불가능 | O 클릭, 입력 등 조작 가능 |
| 크롤링 속도 | 빠름 | 느림 |
3. 파싱(Parsing)
: 가공되지 않은 문자열에서 필요한 부분을 추출하려 (구조화된) 데이터로 만드는 과정
1) HTML(HyperText Markup Language)
: 웹 문서를 작성하는 언어
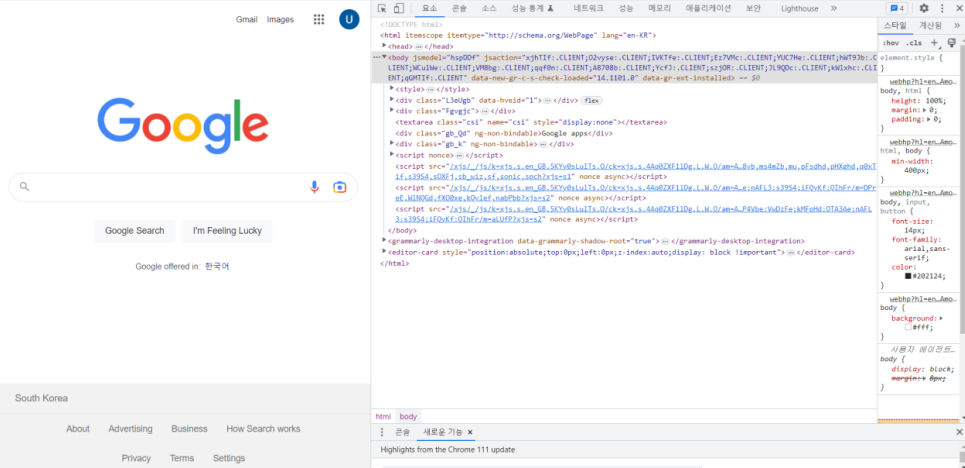
2) Xpath
· Document: HTML 코드를 구성하고 있는 모든 문자열 코드
· Element: Document를 구성하는 단위 (시작 태그와 끝 태그로 구성)

· Tag: Element를 구성하는 단위
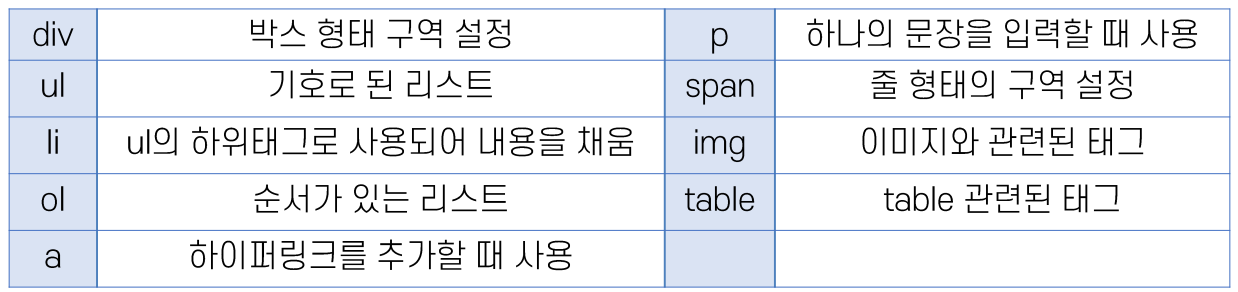
3) CSS
: HTML로 만들어진 화면을 꾸며주는 역할
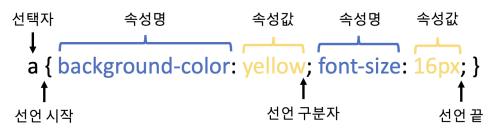
· HTML 지정 태그를 지목해서 속성값(글자색, 크기, 배경색 등)을 넣어주는 것
· 선택지(selector)와 선언부(declaratives)로 구성
4) CSS Selector
: HTML의 element를 선택하기 위한 방법
· div : 태그 선택
· #wrap : id 선택
· .wrap : class 선택
· [data="python"] : attr 선택
· 혼합 선택도 가능
- tag + id : input#query → input 태그 중, id의 속성값이 query인 태그 선택
- tag + class : p.title → p 태그 중, class의 속성값이 title인 태그 선택
· 계층적 구조로 선택
- #wrap > .txt : 바로 한 단계 하위 엘리먼트에서 검색
- #wrap .txt : 모든 하위 엘리먼트에서 검색
5) 정적 / 동적 웹페이지
① 정적 웹페이지
: 서버에 미리 저장된 파일을 그대로 전달되는 웹페이지
· 정적 데이터: 한 페이지 안에서 원하는 정보가 모두 드러날 때, 변하지 않는 데이터

② 동적 웹페이지
: url만으로는 들어갈 수 없는 페이지
(들어가지더라도 url의 변화가 없는데도, 실시간으로 내용이 계속해서 추가되거나 수정되는 경우)
· 동적 데이터: 입력, 출력, 로그인 등과 같이 페이지 이동이 있어야 보이는 데이터
ex) 네이버 메일함, 구글 지도, 유튜브
③ 정적 크롤링 vs 동적 크롤링
| 정적 크롤링 | 동적 크롤링 | |
| 연속성 | 주소를 통해 단발적으로 접근 | 브라우저를 사용하여 연속적으로 접근 |
| 크롤링 커버리지 | 정적 웹페이지 | 정적/동적 웹페이지 |
| 수집 능력 | 수집 데이터의 한계가 존재 | 수집 데이터의 한계가 없음 |
| 속도 | 빠름(별도 페이지 조작 필요x) | 느림 |
| 라이브러리 | requests, BeautifulSoup | Selenium, chromedriver |
다른 프로젝트할 때, 오픈 API를 가끔 사용했었다. 잘만 활용한다면 엄청난 결과를 만들어낼 수 있다.
[Part 2] Open API
1. API(Application Programming Interface)란?
: 특정 프로그램을 만들기 위해 제공되는 모듈(함수 등)
· 어떤 요청인지 구분할 수 있도록 하는 체계
· 클라이언트, 서버와 같은 서로 다른 프로그램에서 요청과 응답을 주고받을 수 있게 만든 체계

1) Open API
: 누구나 사용할 수 있도록 공개된 API
- 데이터를 표준화하고 프로그래밍해 외부 소프트웨어 개발자나 사용자들과 공유
- 주로 Rest API 기술을 많이 사용
2) Rest API (Representational State Trasfer API)
: HTTP 프로토콜을 통해 서버 제공 지능을 사용할 수 있는 함수
- 일반적으로 XML, JSON 형태로 응답을 전달 (원하는 데이터 추출이 수월)

2. Open API 사용법
1) 사용
· 업데이트가 빈번하고 이용자가 많은 대용량 데이터를 제공해야 할 때, 공공데이터 포털을 통한 계정 발급 필요할 때
· 날씨나 교통 정보 등 실시간 업데이트되는 데이터를 제공받을 수 있음
· 소포트웨어 개발자나 사용자들이 쉽게 활용 가능 → 개발 비용 절감, 개발 기간 단축

2) JSON
: 서버/클라이언트 또는 컴퓨터/프로그램 사이에 데이터를 주고받을 때 사용하는 데이터 포맷
· JC론과 같이 간단한 기호로 구성하여 표현 가능
· 언어나 운영체제 구애 X
3) XML
· BeautifulSoup으로 HTML과 동일하게 읽고, 파싱 가능
· 이외에 ElementTree 라이브러리 활용
· 기본 구조: <태그 속성 = "속성값"> 내용
※ 해당 카테고리는 딥노이드, 오픈놀, 앙트비에서 주최하는 '<스타트업 유니버시티: DX Challenge 교육> AI+X 역량 강화 트랙'에 대한 기록입니다.
'[AI+X 역량 강화] 인공지능 > 1) 기본기: 파이썬, 데이터 수집' 카테고리의 다른 글
| [파이썬]#12 동적 크롤링 실습 // 구독한 네이버 뉴스 크롤링 (0) | 2023.09.01 |
|---|---|
| [파이썬]#11 정적 크롤링 실습 // 네이버 뉴스, 서울특별시 코로나19 크롤링 (1) | 2023.08.31 |
| #9 데이터 수집 이론 및 활용 // 사례, 데이터3법, 비식별화 (1) | 2023.08.27 |
| #8 파이썬 기초 6 // Pandas 라이브러리 (0) | 2023.08.27 |
| #7 파이썬 기초 5 // Numpy 라이브러리 (0) | 2023.08.27 |



