드디어 파이썬 기초의 마지막 수업이다.
Pandas는 처음 배우는거라 새로웠다.
몇번 연습해 봐야겠다!
Pandas란?
: R보다 학습이 쉽고, 성능이 좋은 데이터 분석용 라이브러리 (Numpy를 개량한 라이브러리)
- Series : index, value
- DataFrame : index, column, value
0. 라이브러리 불러오기
import pandas as pd
import numpy as np1.Series
동일한 데이터 타입의 값을 갖는다.
1-1. Series 선언
- 동일한 타입만 있을 경우 dtype이 나옴
- 데이터값이 각각 다른 타입 가능
- 참고) nunpy ndarray는 같은 타입만 가능

1-2. index 설정
- 꼭 딕셔너리 타입일 필요 없음
- 0부터 시작

1-3. Series value 출력

1-4. Series Broadcasting ★

1-5. Data Slicing

2. DataFrame
- 여러개의 Series로 구성
- 같은 컬럼에 있는 value값은 같은 데이터 타입을 갖는다.
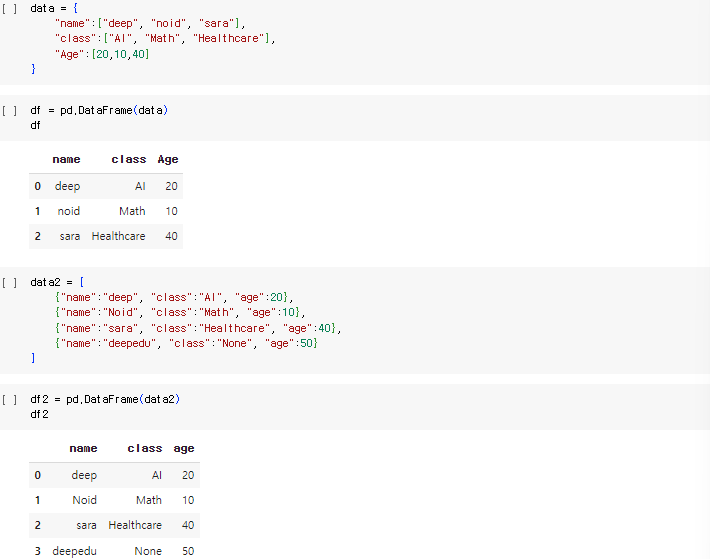
2-1. 인덱스 (index)
인덱스 변경

2-2. DataFrame 데이터 선택

2-2.1. row 선택 후 특정 column 선택

2-2.2. column 선택

2-2.3. index 번호로 출력

2-2.4. index명과 column명으로 출력

2-2.5. 컬럼 데이터 순서 설정

2-3. DataFrame 데이터 추가

2-3.1. column 데이터 추가

2-3.2. row 데이터 수정

2-3.3. head, tail

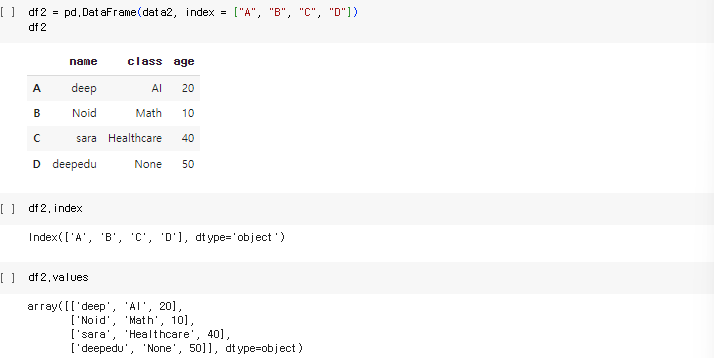
2-3.4. apply 함수 (map 함수와 비슷)
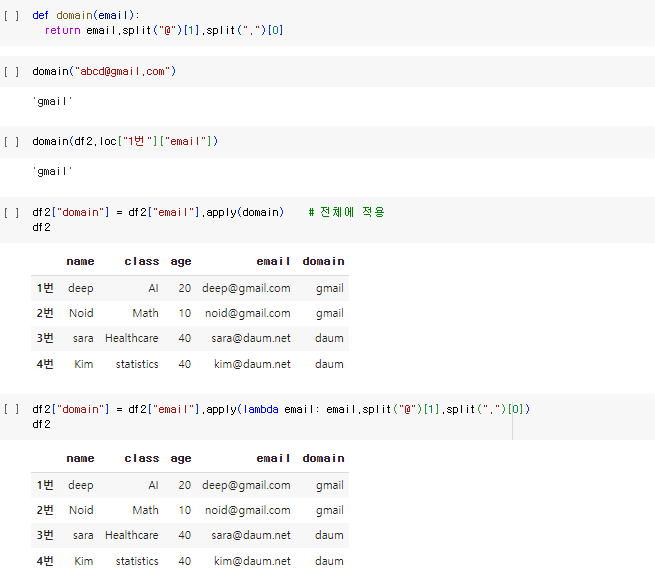
2-4. DataFrame 데이터 삭제
2-4.1. row 삭제
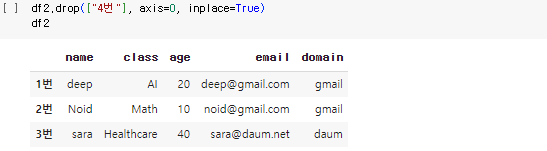
2-4.2. column 삭제

2-5. DataFrame 조건별 출력

2-6. DataFrame concat(붙이기)
- row나 column으로 데이터프레임을 합칠때 사용
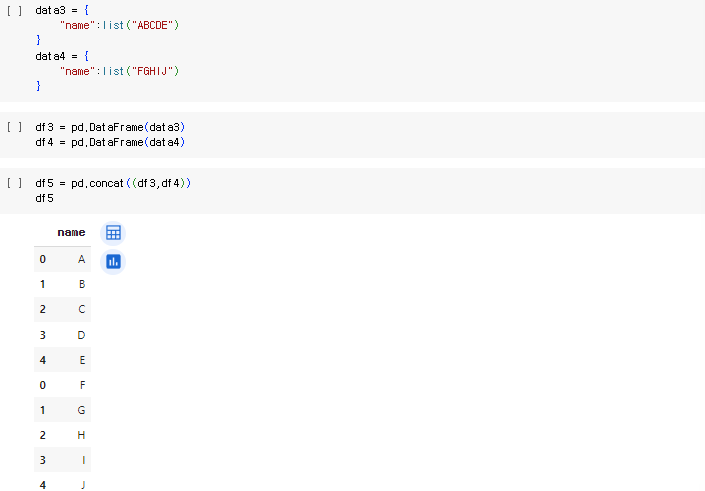
2-6.1. reset_inedex 인덱스 재정렬

2-7. DataFrame 중복 없이 데이터 합치기
- group by : 특정 컬럼의 중복되는 데이터를 합쳐서 새로운 데이터 프레임을 만드는 방법

2-7.1. sort_values : 설정한 컬럼으로 데이터 프레임을 정렬

- size(), min(), max(), mean() : 그룹함수


2-8. DataFrame Merge

dict로 DataFrame 생성

list로 DataFrame 생성

2-8.1. merge parameters
- on: 두 데이터 프레임에 공통으로 속하는 column을 기준으로 병합
- how
- inner : 기준이 되는 column의 데이터가 양쪽 데이터 프레임에 공통으로 존재하는 교집합의 병합
- outer : 기준이 되는 column의 데이터가 한쪽에만 존재해도 포함하여 병합
- left : 왼쪽 데이터프레임으 기준 column에 속하는 값을 기준으로 병합
- right : 오른쪽 데이터프레임의 기준 column에 속하는 값을 기준으로 병합
- left_on / right_on : 각각의 데이터프레임에서의 기준 column을 설정하여 병합
- left_on / right_on으로 설정한 기준 column에 how의 옵션 값으로 기준을 결정하여 병합

2-8.2. DataFrame 정렬

2-9. 데이터 불러오기
- pandas 패키지 안에는 csv 파일 외에 다양한 파일을 불러올 수 있습니다.
- csv 파일을 DataFrame으로 생성하기 위해서는 column명과 index가 존재하면 좋음
- 데이터 프레임을 저장, 로드
- Dacon
- 데이터 분석, 모델을 경쟁할 수 있도록 만든 국내 서비스
- https://dacon.io/

2-9.2. header parameter

2-9.3. header=None 설정 후 names 생성

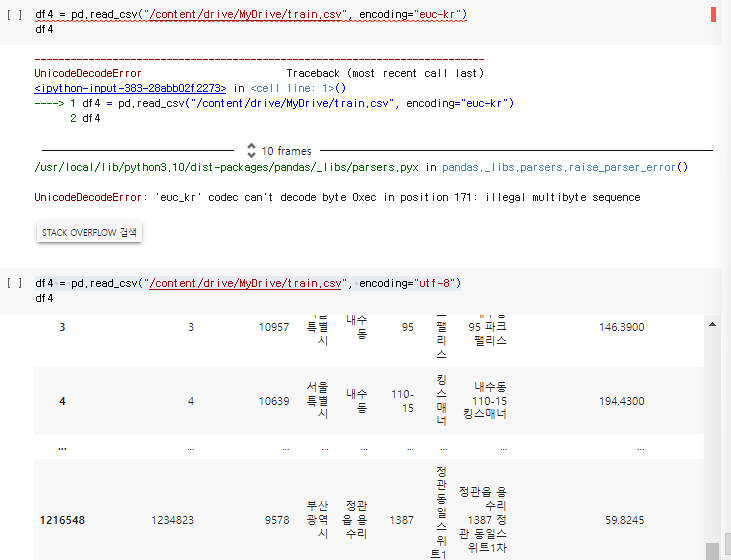
2-9.4. encoding parameter
- 한국어는 euc-kr 또는 utf-8
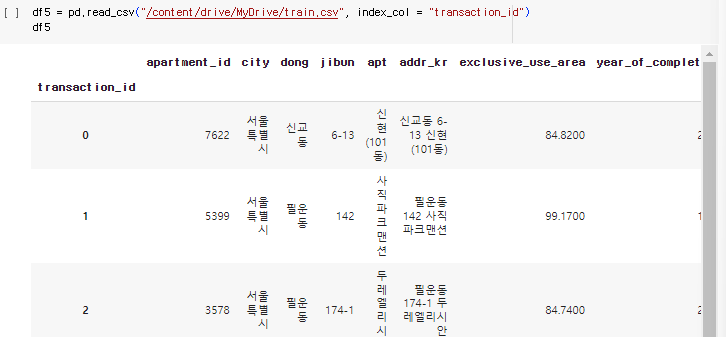
2-9.5. index_col 설정
2-9.6. 저장(save)

2-10. Pandas Pivot
- 데이터 프레임의 컬렘 데이터에서 index, column, value를 선택해서 데이터프레임을 만드는 방법
- df.pivot(index, columns, values)
- groupby 한 후 pivot 실행
- df.pivot_table(values, index, columns, aggfuction)



※ Seaborn
- 나눔바름고딕폰트로 변환하는 코드
- 코랩에서 한글 폰트가 깨질 경우 사용
!sudo apt-get install -y fonts-nanum
!sudo fc-cache -fv
!rm ~/.cache/matplotlib -rf
import matplotlib.pyplot as plt
import seaborn as sns

※ 해당 카테고리는 딥노이드, 오픈놀, 앙트비에서 주최하는 '<스타트업 유니버시티: DX Challenge 교육> AI+X 역량 강화 트랙'에 대한 기록입니다.
'[AI+X 역량 강화] 인공지능 > 1) 기본기: 파이썬, 데이터 수집' 카테고리의 다른 글
| #10 웹크롤링, Open API란? (0) | 2023.08.30 |
|---|---|
| #9 데이터 수집 이론 및 활용 // 사례, 데이터3법, 비식별화 (1) | 2023.08.27 |
| #7 파이썬 기초 5 // Numpy 라이브러리 (0) | 2023.08.27 |
| #6 파이썬 기초 4 // 클래스, 예외처리, 매직 메서드 (0) | 2023.08.26 |
| #5 파이썬 기초 3 // 함수 문법 정리 (0) | 2023.08.25 |



