오늘은 네이버 뉴스로 동적 크롤링 실습을 진행했다.
확실히 정적 크롤링보다 실행 속도가 느리고, 뭔가 더 복잡하다...
HTML을 아예 모르면 좀 헷갈릴 것 같다. (다행히 나는 인터넷활용 수업으로 HTML과 JavaScript를 배웠음!)
근데 자꾸하다보면 그냥 비슷한 반복 작업이라는 것을 알 수 있긴 하다!
동적 크롤링은 처음해보는 거라, 내가 구독한 신문사를 바꿔가며 몇번이나 다시 해봤다.
코드는 같은데 매번 다른 결과가 나오는 것이 신기하기도?!
단점은 뭔가 오류가 있으면 거의 처음부터 다시 실행해야한다는거...
동적 크롤링은 url만으로는 들어갈 수 없는 페이지에서 데이터를 가져올 때 사용된다.
(들어가지더라도 url의 변화가 없는데도, 실시간으로 내용이 계속해서 추가되거나 수정되는 경우)
동적 크롤링을 진행하려면 가장 먼저 ChromeDriver를 다운받아야한다.
[Chrome 접속 > Chrome 맞춤설정 및 제어(우상단) > 도움말 > Chrome 정보]으로 들어가면 내 크롬 버전 정보가 나온다.
다만, 115 버전부터는 크롬에 내장되어 있어서 따로 드라이버 다운이 필요없다.
나는 116 버전이라 따로 다운 받을 필요가 없었는데, 만약 114 이하라면 들어가서 다운받으면 된다.
그리고 오늘은 코랩이 아닌 저번에 다운받은 주피터 노트북에서 진행한다.
[Part 1] 기사 하나에 대한 데이터 크롤링하기
1. 모듈 불러오기
'pyperclip'은 파이썬에서 클립보드를 쉽게 활용할 수 있게 해주는 외부 모듈이다. 네이버 사이트는 time.sleep()을 사용해서 아이디 패스워드 입력시간을 늦춰도 봇임을 탐지하고 자동입력방지 문자를 입력하라고 한다. 따라서 복사 붙여놓기 하는 방식인 pyperclip을 사용하면 가능해진다.
! pip install pyperclip selenium beautifulsoup4 pandas webdriver_managerimport pyperclip
import time
from time import sleep
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service as ChromeService
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.support import expected_conditions as EC
from bs4 import BeautifulSoup as bs
import pandas as pd
2. 네이버로 이동
유저 에이전트를 헤드로 설정하는 것이 필수이기 때문에 user agent를 가져와야한다.
https://www.whatismybrowser.com/detect/what-is-my-user-agent/
Options= webdriver.ChromeOptions()
# 유저 에이전트를 헤더로 필수
user_agent= "본인 유저 에이전트"
Options.add_argument('user-agent=' + user_agent)
driver = webdriver.Chrome(service=ChromeService(executable_path=ChromeDriverManager().install()),options=Options)
# driver.maximize_window()
url = 'https://nid.naver.com/nidlogin.login'
driver.get(url)
time.sleep(1)실행하면 크롬에서 'Chrome이 자동화된 테스트 소프트웨어에 의해 제어되고 있습니다.'라면서 네이버 창이 새로 뜬다.
이때부터는 새로 뜬 창을 옆에 같이 띄워두면서 보면, 실시간으로 변화하는 사이트 화면을 볼 수 있다.
3. 아이디 패스워드 입력
id = "본인 네이버 아이디"
pw = "본인 네이버 비밀번호"
4. 아이디 복사 붙여넣기
tag_id = driver.find_element(By.CSS_SELECTOR, value="#id")
tag_id.clear()
time.sleep(1)
tag_id.click()
pyperclip.copy(id)
# 윈도우 유저
ActionChains(driver).key_down(Keys.CONTROL).send_keys('v').key_up(Keys.CONTROL).perform()
# 맥 유저
# ActionChains(driver).key_down(Keys.COMMAND).send_keys('v').key_up(Keys.COMMAND).perform()
5. 비밀번호 복사 붙여넣기
tag_pw = driver.find_element(By.NAME, 'pw')
tag_pw.clear()
time.sleep(1)
tag_pw.click()
pyperclip.copy(pw)
# 윈도우 유저
ActionChains(driver).key_down(Keys.CONTROL).send_keys('v').key_up(Keys.CONTROL).perform()
# 맥 유저
# ActionChains(driver).key_down(Keys.COMMAND).send_keys('v').key_up(Keys.COMMAND).perform()
time.sleep(1)이런 식으로 뜨고 있으면 잘되어 있는 것임.
6. 로그인 상태 유지
driver.find_element(By.CSS_SELECTOR, value=".keep_text").click()
7. 로그인 버튼 클릭
login_btn = driver.find_element(By.ID, 'log.login')
login_btn.click()
time.sleep(2)
8. 네이버 뉴스로 이동
url = "https://news.naver.com/"
driver.get(url)
9. 네이버 구독 뉴스 url 가져오기
만약 구독한 언론사가 없으면 아무거나 하나 구독해두기. 나는 매일신문으로 했다.
참고로 나중에 댓글도 크롤링 해올 건데, 좀 인기있는 언론사로 구독하는 것이 좋다.
hrefs = []
aTags = driver.find_elements(by=By.CSS_SELECTOR, value = ".cc_text_list > .cc_text_item > a ")
for aTag in aTags: #전체 글 1페이지 url 모두 가져오기
herf = aTag.get_attribute('href') # a 태그의 href
hrefs.append(herf)
hrefs
10. 기사로 이동
driver.get(hrefs[1])내가 이동한 기사는 여기다.
11. 기사 정보 가져오기
우선, CCS_Selector를 사용하여 value를 가져오는 방법은 크롬의 개발자 도구를 사용하면 된다.
예를 들어, 제목을 가져오려면 개발자 도구의 좌상단에 있는 화살표를 누르거나, [Ctrl+Shift+C]를 누르고 기사의 제목을 누르면 된다.
그러면 개발자 도구에서 해당하는 곳으로 찾아가게 되고, Copy > Copy selector를 하면 된다.
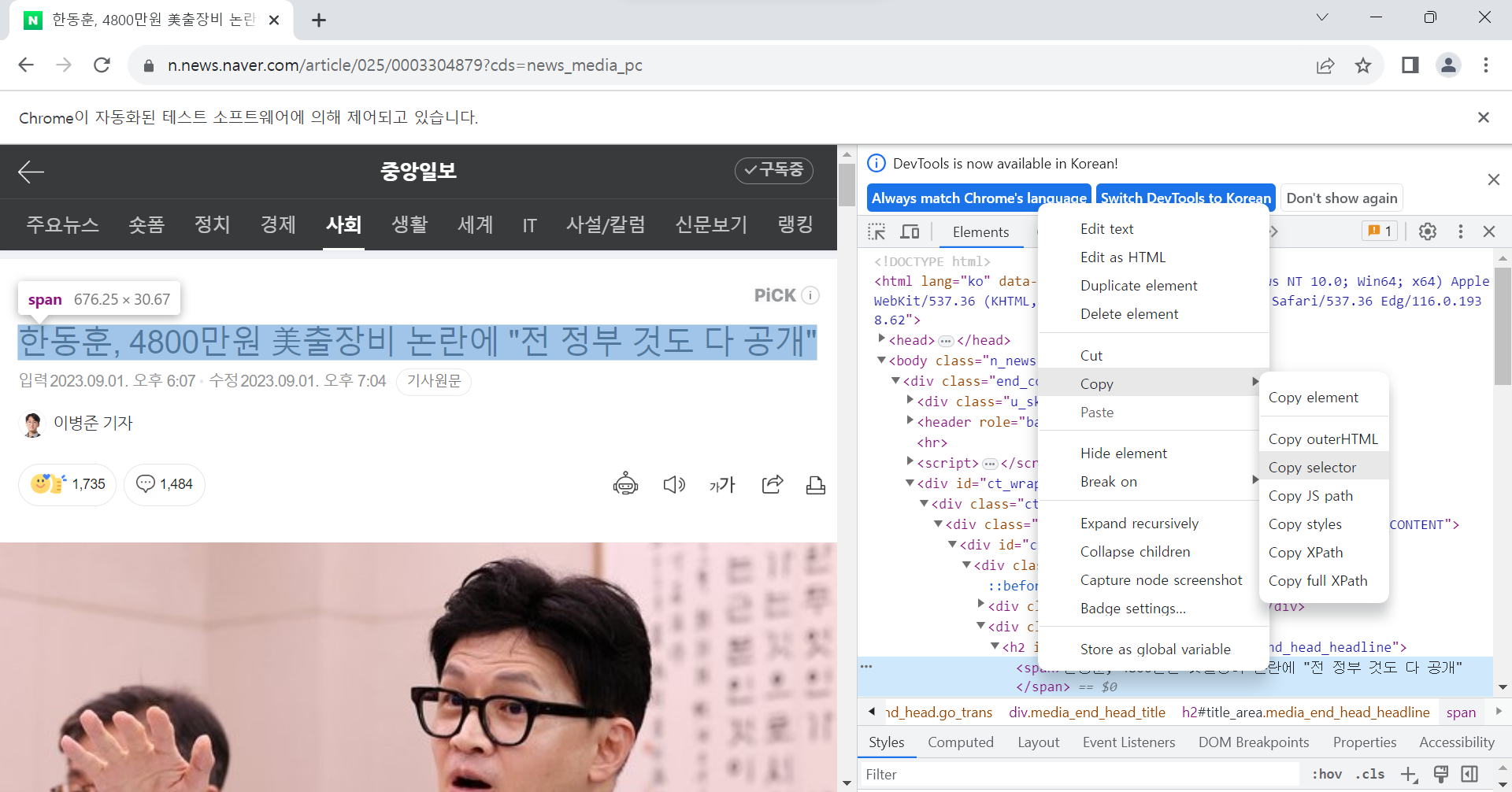
11-1. 기사 제목 가져오기
기사 제목은 대부분 #title_area > span 이다.
article_ti = []
article_titles = driver.find_elements(by=By.CSS_SELECTOR, value = "#title_area > span")
for article_title in article_titles:
article_ti.append(article_title.text)11-2. 기사 기자 이름 가져오기
article_jo = []
article_journalists = driver.find_elements(by=By.CSS_SELECTOR, value = "#ct > div.media_end_head.go_trans > div.media_end_head_info.nv_notrans > div.media_end_head_journalist > a > em")
for article_journalist in article_journalists:
article_jo.append(article_journalist.text)11-3. 기사 내용 가져오기
기사 본문의 value도 보통 #dic_area이다.
article_co = []
article_contents = driver.find_elements(by=By.CSS_SELECTOR, value = "#dic_area")
for article_content in article_contents:
article_co.append(article_content.text)
12. 기사 댓글 가져오기
12-1. 기사 댓글 수 가져오기
comment_numbers = driver.find_elements(by=By.CSS_SELECTOR, value = "#cbox_module > div.u_cbox_wrap.u_cbox_ko.u_cbox_type_sort_new > div.u_cbox_head > a > span.u_cbox_count")
comment_num = []
for comment_number in comment_numbers:
comment_num.append(comment_number.text)12-2. 댓글 내용 가져오기
article_ls= []
driver.implicitly_wait(20)
comment_contents = driver.find_elements(by=By.CSS_SELECTOR, value = "#cbox_module_wai_u_cbox_content_wrap_tabpanel > ul > li.u_cbox_comment.cbox_module__comment_801979352769101934._user_id_no_4KiNi > div.u_cbox_comment_box.u_cbox_type_profile > div > div.u_cbox_text_wrap > span.u_cbox_contents")
for comment_content in comment_contents:
article_dict={}
article_dict["article_title"] = article_ti[0]
article_dict["article_journalist"] = article_jo[0]
article_dict["article_content"] = article_co[0]
article_dict["comment_number"] = comment_num[0]
article_dict["comment_content"] = comment_content.text
article_ls.append(article_dict)
article_ls이렇게 기사 제목, 기자 이름, 본문 내용, 댓글 수, 댓글 내용에 대한 크롤링 데이터가 나왔다.
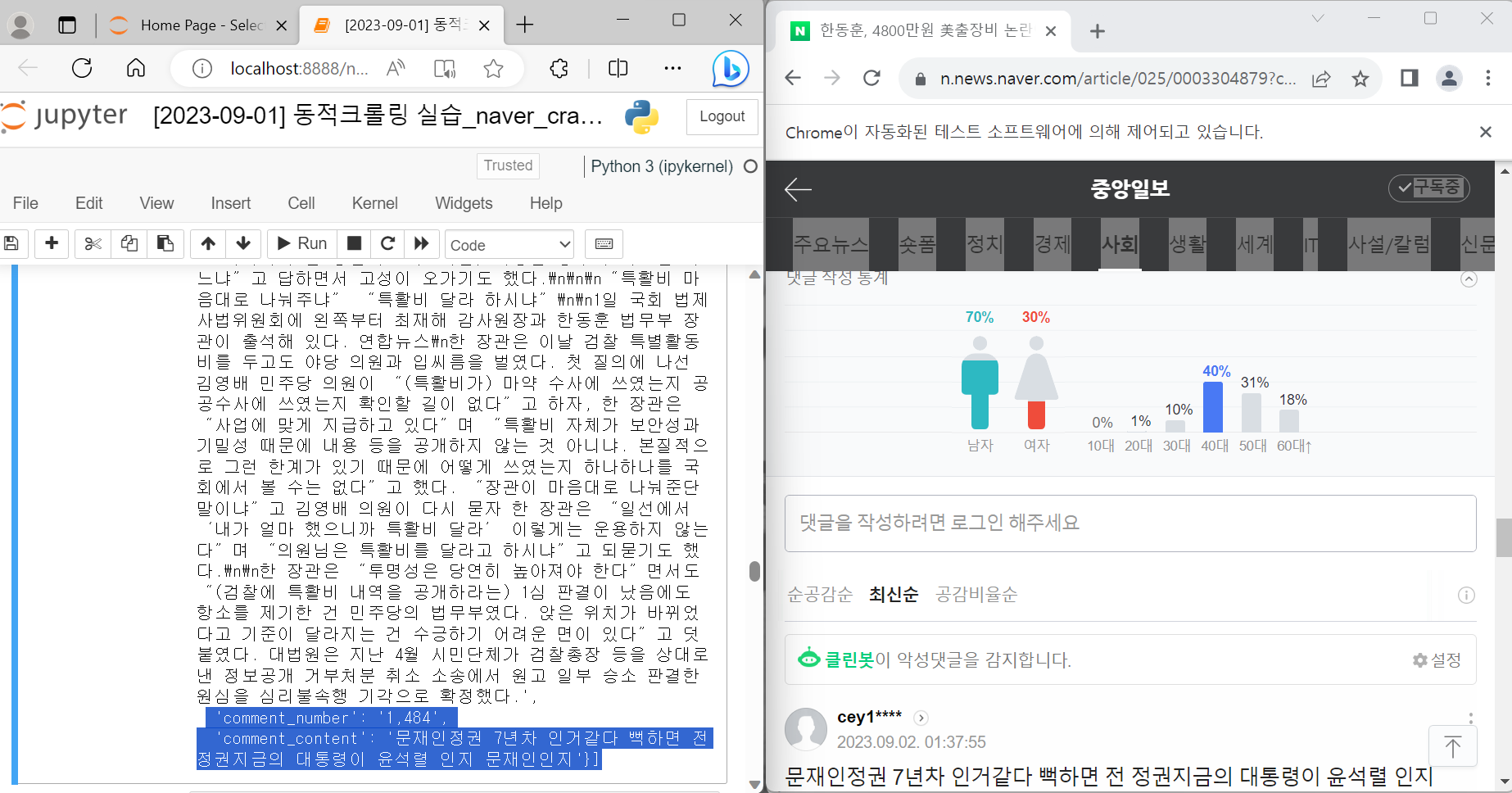
[Part 2] 구독한 언론사의 여러 기사에 대한 내용 한번에 크롤링하기
사실 모든 기사까지는 아니고, 아까 '9. 네이버 구독 뉴스 url 가져오기'에서 나온 url에 대한 데이터다.
1. 여러 기사 데이터 가져오기
def article_crawling(id, pw):
import pyperclip
import time
import pandas as pd
from time import sleep
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service as ChromeService
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.support import expected_conditions as EC
from bs4 import BeautifulSoup as bs
from selenium.common.exceptions import ElementNotInteractableException,NoSuchElementException
Options= webdriver.ChromeOptions()
user_agent= "본인 유저 에이전트"
Options.add_argument('user-agent=' + user_agent)
driver = webdriver.Chrome(service=ChromeService(executable_path=ChromeDriverManager().install()),options=Options)
# driver.maximize_window()
url = 'https://nid.naver.com/nidlogin.login'
driver.get(url)
time.sleep(1)
tag_id = driver.find_element(By.CSS_SELECTOR, value="#id")
tag_id.clear()
time.sleep(1)
tag_id.click()
pyperclip.copy(id)
# 윈도우 유저
ActionChains(driver).key_down(Keys.CONTROL).send_keys('v').key_up(Keys.CONTROL).perform()
# 맥 유저
# ActionChains(driver).key_down(Keys.COMMAND).send_keys('v').key_up(Keys.COMMAND).perform()
tag_pw = driver.find_element(By.NAME, 'pw')
tag_pw.clear()
time.sleep(1)
tag_pw.click()
pyperclip.copy(pw)
# 윈도우 유저
ActionChains(driver).key_down(Keys.CONTROL).send_keys('v').key_up(Keys.CONTROL).perform()
# 맥 유저
# ActionChains(driver).key_down(Keys.COMMAND).send_keys('v').key_up(Keys.COMMAND).perform()
time.sleep(1)
driver.find_element(By.CSS_SELECTOR, value=".keep_text").click()
login_btn = driver.find_element(By.ID, 'log.login')
login_btn.click()
time.sleep(2)
url = "https://news.naver.com/"
driver.get(url)
hrefs = []
aTags = driver.find_elements(by=By.CSS_SELECTOR, value = ".cc_text_list > .cc_text_item > a ")
for aTag in aTags: #전체 글 1페이지 url 모두 가져오기
herf = aTag.get_attribute('href')
hrefs.append(herf)
article_ls= []
for i in range(len(hrefs)-1):
driver.get(hrefs[i])
comment_num = []
article_ti = []
article_jo = []
article_co = []
article_titles = driver.find_elements(by=By.CSS_SELECTOR, value = "#title_area > span")
article_journalists = driver.find_elements(by=By.CSS_SELECTOR, value = "#ct > div.media_end_head.go_trans > div.media_end_head_info.nv_notrans > div.media_end_head_journalist > a > em")
article_contents = driver.find_elements(by=By.CSS_SELECTOR, value = "#dic_area")
comment_numbers = driver.find_elements(by=By.CSS_SELECTOR, value = "#cbox_module > div.u_cbox_wrap.u_cbox_ko.u_cbox_type_sort_new > div.u_cbox_head > a > span.u_cbox_count")
# 전체 글 1페이지 url 모두 가져오기
for article_title in article_titles:
article_ti.append(article_title.text)
print(article_ti)
for article_journalist in article_journalists:
article_jo.append(article_journalist.text)
print(article_jo)
for article_content in article_contents:
article_co.append(article_content.text)
print(article_co)
for comment_number in comment_numbers:
comment_num.append(comment_number.text)
print(comment_num)
driver.implicitly_wait(10)
# 정책상 댓글이 없는 경우
if len(comment_num) == 0:
print("정책 상 댓글을 가져올 수 없습니다.")
article_dict={}
article_dict["article_title"] = article_ti[0]
if not len(article_jo) == 0:
article_dict["article_journalist"] = article_jo[0]
else:
article_dict["article_journalist"] = ""
article_dict["article_content"] = article_co[0].replace("\n","").replace("\\","")
article_dict["comment_number"] = ""
article_dict["comment_content"] = "정책 상 댓글을 가져올 수 없습니다."
article_ls.append(article_dict)
# 댓글이 없는 경우
elif comment_num[0] =="0":
print("댓글이 없습니다.")
article_dict={}
article_dict["article_title"] = article_ti[0]
if not len(article_jo) == 0:
article_dict["article_journalist"] = article_jo[0]
else:
article_dict["article_journalist"] = ""
article_dict["article_content"] = article_co[0].replace("\n","").replace("\\","")
article_dict["comment_number"] = ""
article_dict["comment_content"] = "댓글이 없습니다."
article_ls.append(article_dict)
# 댓글이 있는 경우
else:
try:
driver.implicitly_wait(10)
comment_plus = driver.find_element(by=By.CSS_SELECTOR, value ="div > .u_cbox_btn_view_comment")
comment_plus.click()
driver.implicitly_wait(10)
except ElementNotInteractableException:
pass
finally:
try:
driver.find_element(by=By.CSS_SELECTOR, value =".u_cbox_page_more").click()
except NoSuchElementException:
pass
except ElementNotInteractableException:
pass
finally:
driver.implicitly_wait(20)
comment_contents = driver.find_elements(by=By.CSS_SELECTOR, value = "#cbox_module_wai_u_cbox_content_wrap_tabpanel > ul > li.u_cbox_comment.cbox_module__comment_801979352769101934._user_id_no_4KiNi > div.u_cbox_comment_box.u_cbox_type_profile > div > div.u_cbox_text_wrap > span.u_cbox_contents")
for comment_content in comment_contents:
article_dict={}
article_dict["article_title"] = article_ti[0]
if not len(article_jo) == 0:
article_dict["article_journalist"] = article_jo[0]
else:
article_dict["article_journalist"] = ""
article_dict["article_content"] = article_co[0].replace("\n","").replace("\\","")
article_dict["comment_number"] = comment_num[0]
article_dict["comment_content"] = comment_content.text
article_ls.append(article_dict)
driver.quit() # 드라이버 종료 코드아래의 이 짧은 코드 한 줄을 실행하는 것이 정말 오래걸린다...
그치만 결과만 나오면 거의 다 한거나 마찬가지니까 여유를 가지고 기다리자.
article_crawling(id, pw)
2. 가져온 내용 데이터화하기
위에가 너무 오래 걸려서 일단 아까 파트1에서 한 걸로 진행했다.
article_ls
3. 데이터 프레임에 넣기
df = pd.DataFrame(article_ls)
print(df)파트 1에서 진행한 부분만 나와서 인텍스가 0 하나지만, 여러 기사로 하게 되면 더 많은 인덱스가 추가되면서 내용이 많아진다.

4. 엑셀로 저장하기
엑셀에 저장하기 위해서 opendpyxl을 꼭 설치해야한다.
!pip install openpyxldf.to_excel("./네이버 뉴스.xlsx", encoding="euc-kr")
※ 해당 카테고리는 딥노이드, 오픈놀, 앙트비에서 주최하는 '<스타트업 유니버시티: DX Challenge 교육> AI+X 역량 강화 트랙'에 대한 기록입니다.
'[AI+X 역량 강화] 인공지능 > 1) 기본기: 파이썬, 데이터 수집' 카테고리의 다른 글
| [파이썬]#13 OpenAPI 크롤링 실습 // 서울 열린데이터 광장, 표와 그래프 만들기 (0) | 2023.09.02 |
|---|---|
| [파이썬]#11 정적 크롤링 실습 // 네이버 뉴스, 서울특별시 코로나19 크롤링 (1) | 2023.08.31 |
| #10 웹크롤링, Open API란? (0) | 2023.08.30 |
| #9 데이터 수집 이론 및 활용 // 사례, 데이터3법, 비식별화 (1) | 2023.08.27 |
| #8 파이썬 기초 6 // Pandas 라이브러리 (0) | 2023.08.27 |



