오늘은 requests 모듈, BeautifulSoup 라이브러리, pandas 라이브러리를 이용하여 코랩에서 크롤링을 진행해볼 것이다.
우선, 네이버 웹사이트로 간단한 방법을 알아보자.
첫번째 실습은 서울특별시 코로나19 홈페이지에서 정보를 가져와, 표로 만들고, 엑셀로 저장하는 방법까지 실습해보자.
두번째 실습으로는 네이버 뉴스에서 어떤 키워드를 입력하면 기사의 제목들을 표로 불러올 것이다.
[Part 1] 정적 웹크롤링 방법 예제 실습
1. (방법1) Requests 모듈
- html 문서를 가져올때 사용하는 패키지
- 사용자 친화적인 문법을 사용하여 다루기 쉬우면서 안정성이 뛰어남
- 파이썬 기본 라이브러리에 포함된 urllib 패키지보다 자주 사용방법
· Colab에서는 이미 설치되어 있는 상태이기 때문에 따로 설치 불필요
· 개인적으로 사용할때 local 터미널 창에서 pip install requests 입력
· 만약 anaconda를 사용하신다면 pip 대신 conda를 입력

2. (방법2) BeautifulSoup 모듈 - find(), select()
- 매우 길고 정신없는 html 문서를 잘 정리되고 다루기 쉬운 형태
- 만들어져 원하는 것만 선택해서 가져올 때 사용 - 파싱(parsing)
· Colab에서는 이미 설치되어 있는 상태이기 때문에 따로 설치 불필요
· 개인적으로 사용할때 local 터미널 창에서 pip install beautifulsoup4 입력
· 만약 anaconda를 사용하신다면 pip 대신 conda를 입력

1) find()
- find는 하나만 찾는 것, find_all은 모두 다 찾는 것
- find로 찾는 것이 중복이라면 가장 첫번째 것만 가져오기 때문에 주의
- 괄호() 안에는 html 태그(tag)나 속성(attribute)이 들어감.
① find_all('tag_name') : 태그 이름으로 엘러먼트 찾기

② find_all('css_class_name') : CSS 클래스 명으로 엘레먼트 찾기

③ find('css_id') : CSS id명으로 엘레먼트 찾기

④ find("태그 이름", "속성명") : CSS 태그이름과 속성명으로 엘레먼트 찾기
2) select()
- 괄호 ()안에 CSS 선택자를 넣어서 원하는 정보를 찾음
- select() : find_all()과 같은 개념
- select_one() : find()와 같은 개념
- select("css_셀렉터") : CSS 셀럭터 문법으로 엘레먼트 찾기(배열로 반환)
- select_one("css_셀렉터") : 하나의 엘레먼트만 반환

[Part 2] 실습1. 서울특별시 코로나19 홈페이지에서 정적 웹크롤링
참고로, 2023년 8월 30일에 실습한거라, 이 날짜 기준 정보이다.

1. [Pandas] pd.read_html() :: html에서 표 가져오기/데이터프레임으로 만들기
- pandas란?
- 파이썬에서 사용할 수 있는 데이터분석 라이브러리
- 행과 열로 이루어진 데이터 객체를 만들어 다룸
- 보다 안정적으로 대용량의 데이터를 처리하는데 매우 편리한 도구
- pandas 데이터 구조
- pandas는 3종류(Series, DataFrame, Panel)의 데이터 구조를 제공
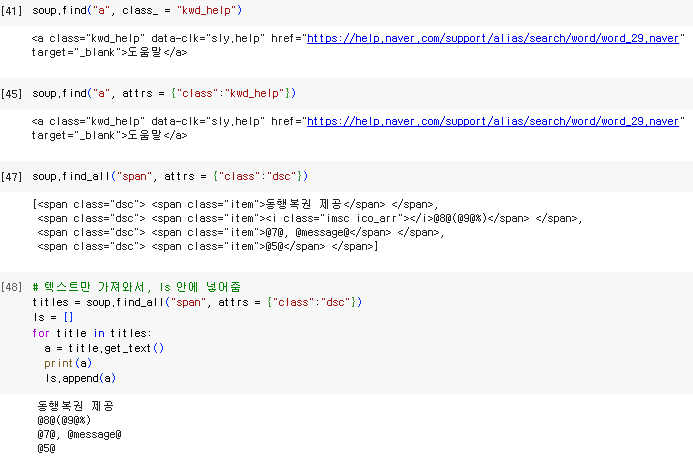
- 주로 Series(1차원)와 Data Frame(2차원)을 사용
- Dataframe 은 Row, Column, Series로 구성됨.
- excel에서의 표 형식과 유사, 행 부분을 Row이라고 하고, 열 부분을 Column이라고 함.
- Series는 각 Column에 있는 데이터를 의미
참고로, pd.read_html을 이용하면 html에 있는 table속성에 해당하는 값을 가져올 수 있다. 이는 웹페이지에 있는 표를 불러오겠다는 의미한다.
1) pandas 모듈 불러오기
import pandas as pd2) URL 가져오기
url = "https://www.seoul.go.kr/coronaV/coronaStatus.do"3) pd.read_html 이용해서 웹페이지에 표 가져오기
table = pd.read_html(url)
table
# 테이블 개수 확인하기
len(table)
4) 가져온 표 보기
주의할 점은 웹 상에 있는 테이블은 가져올 수 있으나, 신규 확진자 누적 확진자 부분 표가 아닌 부분은 가져올 수 없다.
즉, 표 데이터만 가능하다.
table[0]
2. 크롤링 순서
① 목표로 하는 웹 페이지의 html을 requests 패키지를 이용하여 받기
② 가져온 html 문서 전체를 beautifulsoup4 패키지를 이용하여 파싱(parsing)
③ 필요한 정보만 골라서 리스트에 담기
④ 리스트를 print()함수로 출력하거나, excel이나 csv 파일에 저장
1) BeautifulSoup 모듈 불러오기
- 파이썬에서 HTML을 다룰 때 대표적
크롤러에 보통 사용되고, 필요한 데이터를 추출하거나 모니터링 하기 위해 원하는 HTML을 가져올 수 있다.
import requests
from urllib.request import Request, urlopen
from bs4 import BeautifulSoup as bs2) HTTP Status Code 확인
서버와 클라이언트가 데이터를 주고 받으면 주고 받은 결과로 상태 코드를 확인할 수 있다.
- 2xx-sucess(성공) : 요청을 성공적으로 받음
- 3xx-redirection(browser cache)(리다이렉션) : 요청 완료를 위한 추가 작업 필요
- 4xx-request error(클리이언트 오류) : 요청의 문법이 잘못되거나 요청을 처리 할 수 없음
- 5xx-server error(서버 오류) : 서버가 명백히 유효한 요청에 대한 충족 실패
url = "https://www.seoul.go.kr/coronaV/coronaStatus.do"
requests.get(url)
ConnectionError: ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response'))는 헤더가 없기 때문에 발생하는 오류이다. 사용자를 크롤링봇으로 의심하기 때문이다.
따라서 크롤링봇이 아니고 정식 유저(?)라는 것을 증명하기 위해 유저 에이전트를 통해 헤더를 넣어줘야 한다.
헤더를 넣었는데도 안되면 쿠키도 넣어주면 된다.
User Agent 확인은 http://m.avalon.co.kr/check.html 로 들어가서 navigator.userAgent 값을 복사하여 넣어주면 된다.
requests.get(url, headers={
"User-Agent" : "navigator.userAgent 값"
})<Response 200>이라는 결과가 나오면 성공!
3) Soup 클래스화
가장 먼저 HTML 데이터를 가져오는데 보통 requests 통신으로 요청을 하여 HTML 코드를 가져온 후 Soup로 만든다. 첫번째 인자로 HTML 코드, 두 번째 인자로 파서 종류를 설정하는데 주로 "html.parser"를 많이 사용한다.
크롬에서 [도구 더보기 > 개발자 도구] 선택에서 html을 보면 된다.
request = Request(url)
page = urlopen(request).read()
soup = bs(page, "html.parser")
soup
4) Direct tag 참고
- title, head, body와 같은 최상단 태그들을 가져올 수 있음
- 무언가를 찾을 때 단순히 전체 soup에서 검색하는 것보다 하위 태그로 한 단계 이동 후 검색하면 효율적

5) find
- 제일 가까운 태그 하나를 찾을 때
- 찾고자 하는 데이터가 하나라면 find 사용 추천
soup.find("div")
6) find_all
- 여러 개의 태그를 가져올 수 있음
- div 태그 목록이 반환되며 반복 구문인 for 문 안에 if 조건문을 넣어 원하는 조건으로 검색 가능
divs = soup.find_all("div")
for div in divs:
print(div.text)
7) 클래스(class)
- 두번째 파라미터 : 찾고자 하는 클래스
- find(태그, CLASS 명) 입력
parse = soup.find("div", "status-seoul")
parse
8) 기간 가져오기
date_raw = parse.find("h4").text
date_raw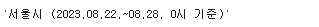
여기서 깔끔하게 날짜만 가져오도록 추가로 정제하자.
date = date_raw[5:-8]
date
9) 신규확진자, 누적확진자, 당일사망자, 누적사망자 정보 가져오기
counters = []
persons = parse.find_all("p", "counter")
for counter in persons:
person = counter.text
counters.append(person)
counters
여기서도 숫자만 가져오도록, \r이나 \t 같은건 지우자.
counters[1] = counters[1].replace("\r", "").replace("\n", "").replace("\t", "")
counters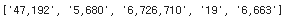
10) 가져온 정보 dictionary에 넣기
- 중괄호 {} 를 사용해서 생성
- 키(key)와 값(value)를 갖는 데이터 구조로 key:value 쌍을 콜론(:) 으로 연결
- 순서가 없음
info = {
"date":date,
"신규확진자":counters[0] + "명",
"전주대비":counters[1] + "명",
"누적확진자":counters[2] + "명",
"당일사망자":counters[3] + "명",
"누적사망자":counters[4] + "명",
}
info
11) dictionary를 사용하여 dataframe 생성
df = pd.DataFrame(info, index=[1])
df
12) DataFrame을 csv 또는 excel 파일로 저장
- csv로 저장하기
df.to_csv("./corona.csv", index=False)
corona_df = pd.read_csv("./corona.csv")
corona_df
- excel로 저장하기
to_excel()를 사용하고, encoding은 보통 "utf-8" 을 사용하지만 한글은 "euc-kr" 으로 호환이 잘된다.
df.to_excel("./corona.xlsx", encoding="euc-kr")
corona_df2 = pd.read_excel("./corona.xlsx")
corona_df2
[Part 3] 실습2. 네이버에서 코로나 관련 뉴스 크롤링
1) 프로젝트에 필요한 패키지 불러오기
from bs4 import BeautifulSoup as bs
import requests2) 크롤링할 url 주소 입력. (네이버에서 코로나 검색 후, 뉴스 탭 클릭)
url = "https://search.naver.com/search.naver?where=news&sm=tab_jum&query=코로나"'코로나'가 아닌 다른 키워드로 다르게 입력하게 할수도 있다.
query = input("검색할 키워드를 입력하시오: ")
url = f" https://search.naver.com/search.naver?where=news&sm=tab_jum&query={query}"
url
3) requests를 이용해 url의 html 문서 가져오기
response = requests.get(url)
html_text = response.text
html_text
4) bs4를 이용해서 html 문서 파싱
soup = bs(html_text, "html.parser")
soup
5) bs4의 find 함수와 선택자 개념을 이용해서 뉴스기사 제목 하나 가져오기
print(soup.find("a", "news_tit").get_text())
6) bs4의 find_all 함수와 선택자 개념을 이용해서 뉴스기사 제목 모두 가져오기
- list
- 순서가 있는 수정가능한 객체의 집합
- 수정, 삭제, 추가가 가능
- [] 대괄호로 작성되어지며, 내부 데이터는 , 로 구분
# dic으로 dataframe 만들기
titles = []
news_titles = soup.find_all("a", "news_tit")
for news_title in news_titles:
title = news_title.get_text()
titles.append(title)
titles
7) list로 dataframe 만들기
df = pd.DataFrame(titles, columns=["titles"])
print(df)
8) dataframe을 cvs 또는 excel로 저장하기
df.to_csv("./naver_news.csv", index=False)
df.to_excel("./naver_newes.xlsx", encoding="euc-kr")
※ 해당 카테고리는 딥노이드, 오픈놀, 앙트비에서 주최하는 '<스타트업 유니버시티: DX Challenge 교육> AI+X 역량 강화 트랙'에 대한 기록입니다.
'[AI+X 역량 강화] 인공지능 > 1) 기본기: 파이썬, 데이터 수집' 카테고리의 다른 글
| [파이썬]#13 OpenAPI 크롤링 실습 // 서울 열린데이터 광장, 표와 그래프 만들기 (0) | 2023.09.02 |
|---|---|
| [파이썬]#12 동적 크롤링 실습 // 구독한 네이버 뉴스 크롤링 (0) | 2023.09.01 |
| #10 웹크롤링, Open API란? (0) | 2023.08.30 |
| #9 데이터 수집 이론 및 활용 // 사례, 데이터3법, 비식별화 (1) | 2023.08.27 |
| #8 파이썬 기초 6 // Pandas 라이브러리 (0) | 2023.08.27 |



