오늘 하루종일 배운 게 너무 많아서 두 개의 글로 나눠 쓴다.
게다가 처음 배우는 내용이고, 진도가 꽤 빨라서 엄청 열심히 들었다.
나는 배운 내용을 정리하면서 실습을 하다 보니까 더 바빴던 것 같다. 그래도 확실히 이해에는 도움이 되는 듯!
그래도 매우 열심히 해서 뿌듯하고, 아침부터 밤까지 집중해서 힘들었는데도 은근 재밌었다.
[Part 1] 지도학습 - 분류(classification)
1. 분류모델의 성능 측정하기
1) 측정 기준①

- 정확도(Accuracy): 전체 데이터에서 제대로 예측한 비율
- 정밀도(Precision): 실제 모든 데이터 중에서 모델이 True라고 분류한 비율
- 재현율(Recall): 실제 True인 데이터 중에서 모델이 True라고 예측한 비율
2) 측정 기준②

목표: 그래프를 Perfect Classifier 점에 최대한 가깝게 끌어당기는 것
- F1-Score: 정밀도와 재현율의 조화평균값
- Fall-Out(FRP, False Positive Rate): 실제 거짓인 데이터에 대해서 모델이 True(FP)라고 예측한 비율
- ROC Curve(Receiver Operating Characteristic): 재현율과 fall-out 간의 변화
- AUC(Area Under Curve): ROC 커브 아래의 영역
2. 학습모델 검증을 위한 데이터 구성

3. 나이브 베이지안(Naive Bayes) 알고리즘
: 사전확률 정보에 기반하여 사후 확률을 추정하는 통계적인 방법
- 혼동 행렬: 알고리즘이 잘 예측했는지, 안 했는지 확인
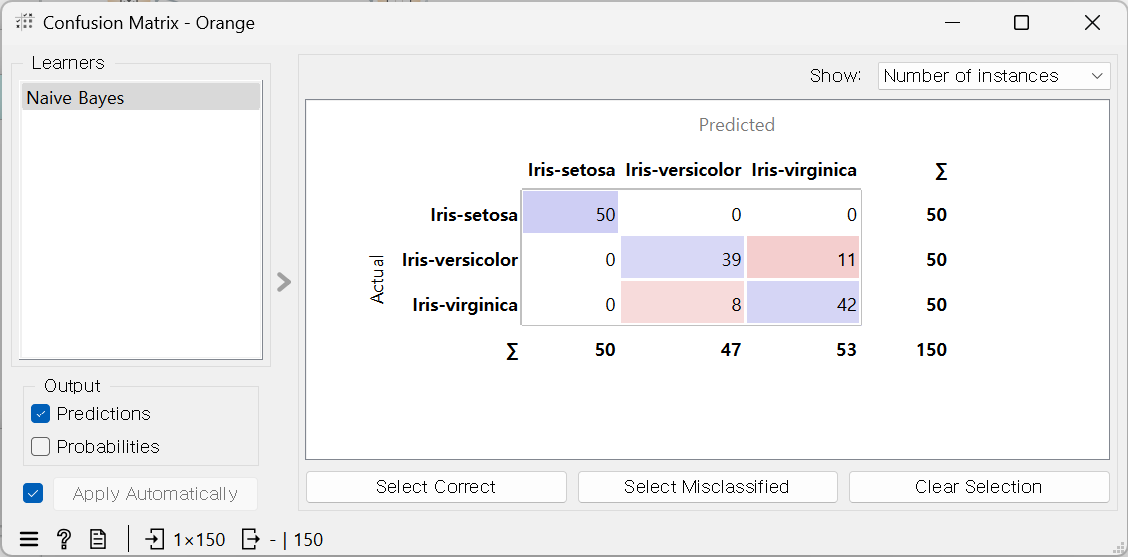
인풋 데이터 70:30으로 나눔 -> 150:45



4. 의사결정트리(DT) 알고리즘
: 탐색과 모델링의 과정을 통해 학습 모델 생성
- 탐색을 통해 의사결정에 유효한 속성(특징)이나 규칙을 찾고, 모델링을 통해 나무 형태를 완성

5. 랜덤 포레스트 (RF) 알고리즘
: 다수의 의사결정트리로부터 구해진 예측/분류값을 사용해서 최종 예측/분류값을 결정

6. 서포팅 백터 머신(SVM)
: 학습데이터에서 분류할 대상을 기준으로 분리할 데이터의 결정 경졔를 정하는 학습 방법 (분류, 회귀분석 가능)
- 서포팅 벡터들로부터의 거리를 통해 마진이 최대가 되는 결정 경계선을 결정

정확도(AUC)가 1이라는 것은 좋은 것이 아니다. 과적합이나 데이터가 너무 적다거나 한다는 의미.
7. K-최근접 이웃 (KNN, K-NearNest)
: 학습데이터세트에 포함된 데이터 간의 거리 관계를 이용해서 데이터를 분류하는 방법

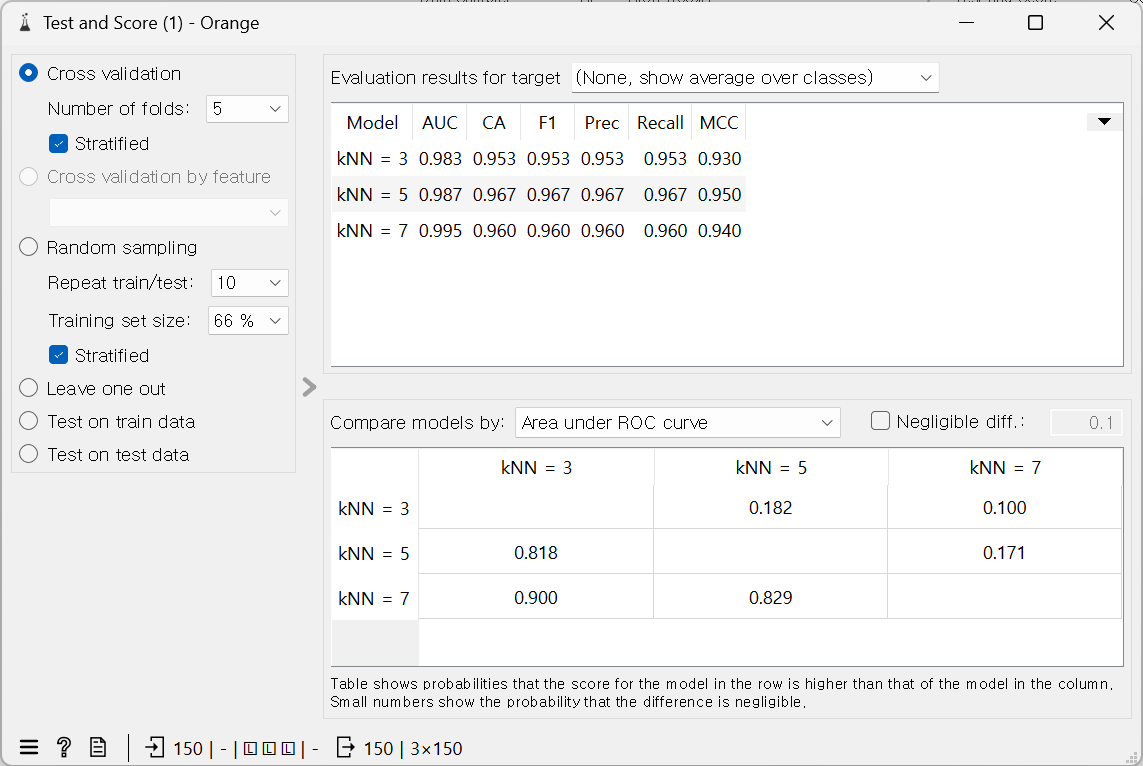
가장 최적의 K는 엘보 메소드를 활용하여 찾는다.




아래처럼 여러 개로도 볼 수 있다. k가 많을수록 성능이 좋은 것을 확인.
[Part 2] 지도학습 - 분류 실습하기
실습 01: 다양한 동물 특징 구분 'Zoo' Dataset
1. 데이터를 로딩하고 통계적 특성 확인하기
2. 데이터를 학습데이터와 테스트 테이터로 분할하기
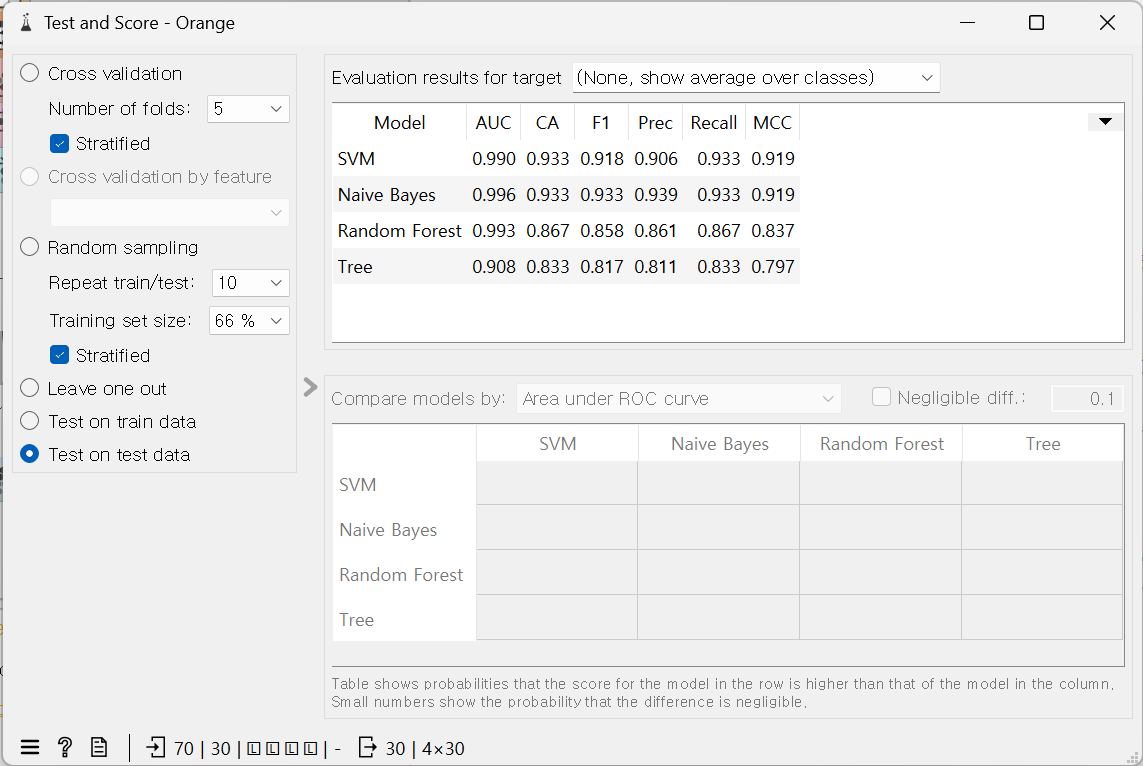
3. 랜덤포레스트를 사용하여 분류하고, 검증 결과 확인
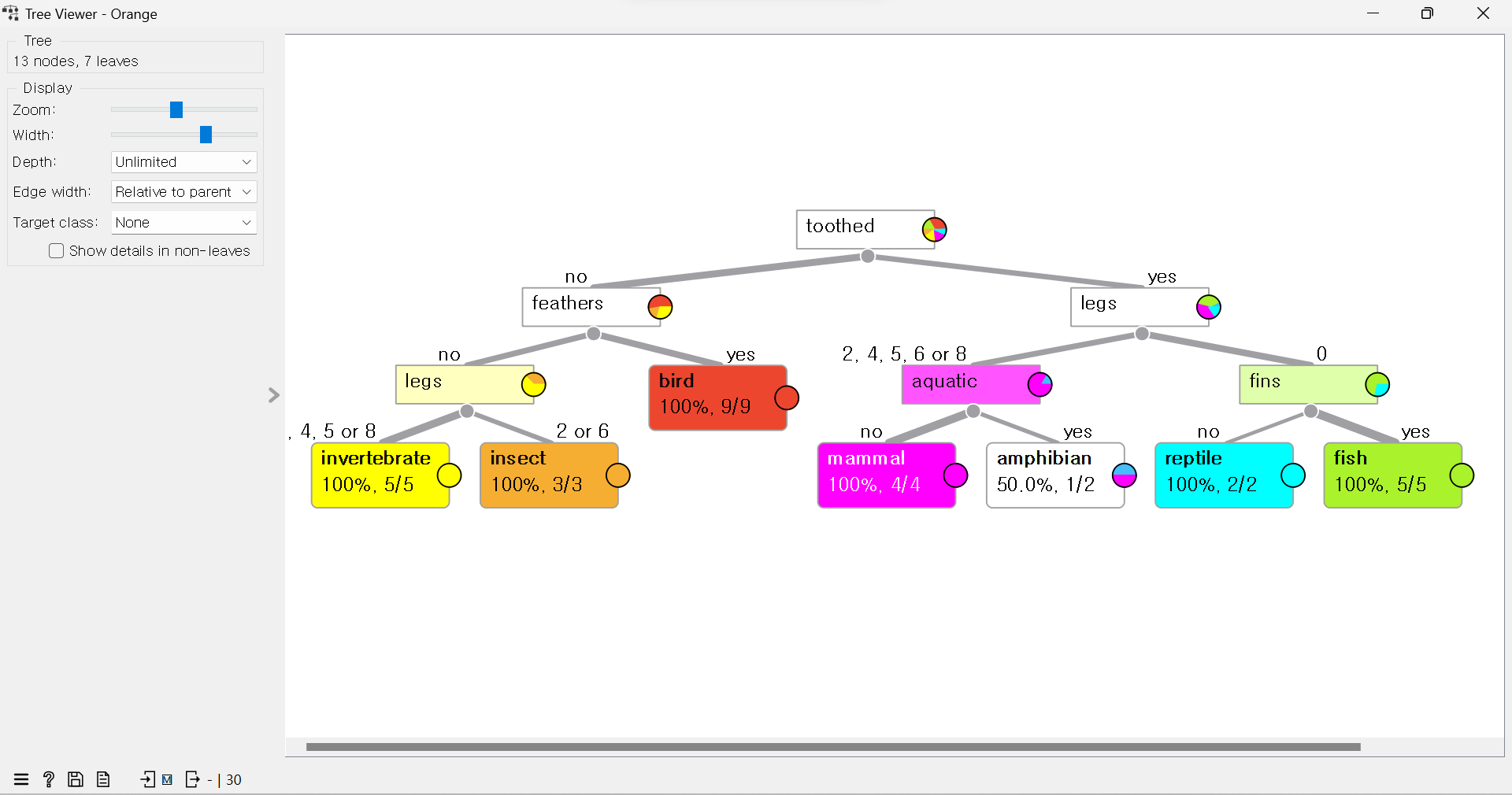
4. RF, 의사결정트리, SVM, Naive Bayes의 모델을 이용하여 검증하기 (트리뷰어로 확인)
5. ROC와 혼동행렬표를 사용하여 분류 결과 확인하기



실습02: 이미지 분류 'Traffic Signs' Data Set
1. 이미지 데이터를 로딩하고 확인, 이미지 뷰어를 사용하여 이미지 확인
2. 로딩된 2차원 이미지를 사전 학습된 모델 사용하여 변환
3. 신경 회로망(Neural Network), RF를 사용하여 분류 결과 확인
4. ROC와 혼동행렬표 확인
5. 이미지백터를 2차원으로 축소, 2차원 그래프로 교통신호 표지판의 분류 내용 확인
6. 차원 축소된 2차원 벡터값을 정규화(평균:0, 분산:1)
7. 차원 축소된 데이터에 대래서 RF와 DT 모델 학습, 혼동행렬 결과
우선, 이미지를 읽을 수 있도록 Images 위젯 추가하기: Options > add-ons > Image
Image Embedding을 통해, 데이터로 변환하기 (Step 2)

[Part 3] 지도학습 - 회귀/예측
독립변수: 원인 / 종속변수: 결과
1. 로지스틱 회귀분석
: 2개의 클래스(종속변수 2개)에 대해서 분류가 아닌 회귀 방식으로 클래스를 예측
- 어떤 사건이 발생할지에 대한 확률로 추정 (0~1 사이의 확률값 출력)

- 선형 회귀의 경우, 아래의 그림에서 타원형으로 표시된 영역에서 오류 발생 (0을 1로, 1을 0으로 분류)
- 로지스틱 회귀는 S자 형태로 2개의 클래스를 구분하고 있어서 분류 오류를 감소시킴

Data Set: 'Housing'
- Linear Regression(선형회기)


· MSE(Mean Square Error): 원래값과 예측값 간의 차이의 제곱의 합에 대한 평균값 (작을수록 좋음)
· RMSE(Root Mean Square Error): MSE 값에 거듭제곱
· MAE(Mean Absolute Error): 원래값과 예측값 간의 차이의 절댓값의 합에 대한 평균값
· R2(결정계수): 모형이 주어진 데이터와 적합한지의 수준 (1에 가까울수록 모형의 유용성이 큼)
- Options > add-ons> Education 위젯 > Polynomial Regression(다항 회기)
▶ Logistic Regression

정칙화(Strength): 데이터에 대해서 크게 민감하게 반응하지 않음 (약할수록 데이터를 민감하게 받아들임)
- 모델의 개수가 너무 작아도 성능이 떨어지지 않음, 과적합 문제 해결
- 이름은 회기지만 분류 알고리즘에 가까움 (확률을 통해서 보기 때문)
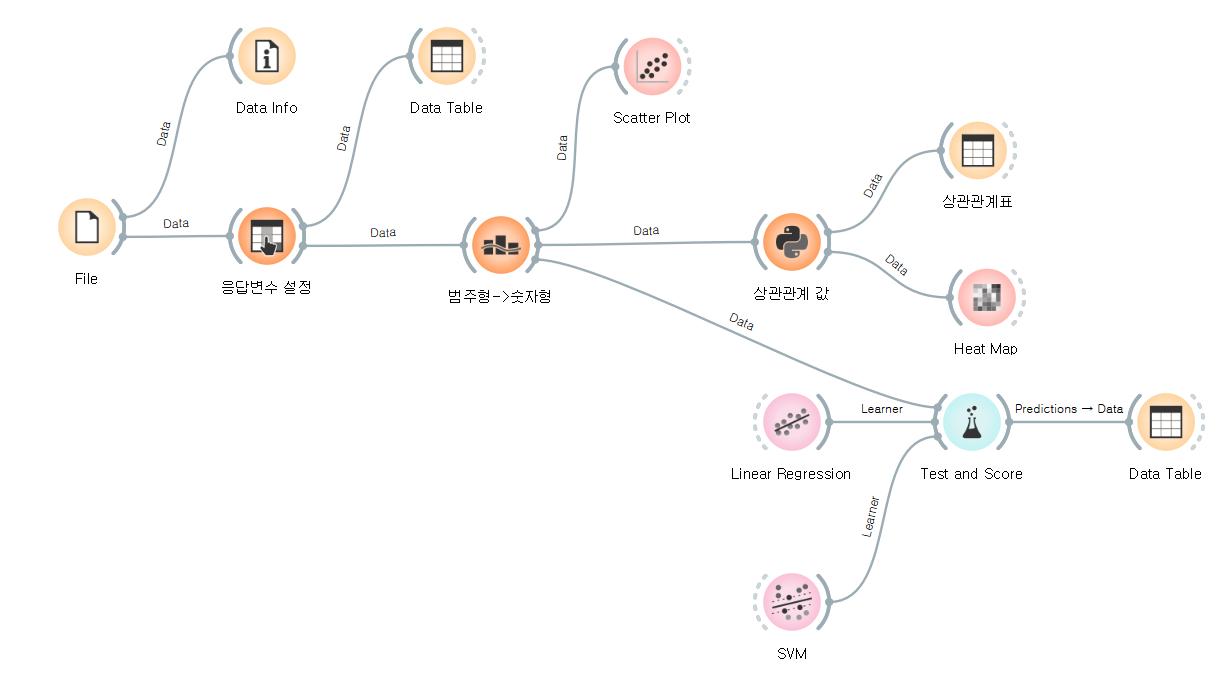
[Part 3] 실습03. 오늘 배운 내용 활용하기
1. CSV포맷의 데이터를 로딩하고 확인
2. 로드된 데이터에서 tip 속성을 목표변수로 설정
3. 범주형 속성을 숫자형으로 변경
4. 데이터 속성 간의 관계를 파악할 수 있도록 그래프에 표시
5. 데이터 속성들 간의 상관관계 값을 계산하고 시각화 (파이썬 코드 스크립트 위젯 사용)
6. 선형회귀와 SVM 모델을 사용하여 예측모델을 학습하고 테스트
7. 예측 결과표로 확인

※ 해당 카테고리는 딥노이드, 오픈놀, 앙트비에서 주최하는 '<스타트업 유니버시티: DX Challenge 교육> AI+X 역량 강화 트랙'에 대한 기록입니다.
'[AI+X 역량 강화] 인공지능 > 3) 실전 챌린지: 스마트 트랜스폼' 카테고리의 다른 글
| 인공지능을 활용한 자율비행 드론 프로그래밍 // Tello Drone (0) | 2023.09.23 |
|---|---|
| 컴퓨터비전을 활용한 자율자동차 AI 프로그래밍#2 // 동키카 데이터 수집 방법 (0) | 2023.09.17 |
| 컴퓨터비전을 활용한 자율자동차 AI 프로그래밍#1 // 동키카로 데이터 수집, 처리, 저장, 학습 (0) | 2023.09.16 |
| 데이터 분석 워크숍(orange3 활용)#3 // 군집화, 앙상블 학습, 팀프로젝트 (0) | 2023.09.10 |
| 데이터 분석 워크숍(orange3 활용)#1 // 기술 통계, 정규화, 범주화, 숫자형 및 범주형 변환 (0) | 2023.09.09 |



