오늘은 주말 동안에 하루종일 진행하는 오프라인 수업 중 첫날이다. 이번 주말은 orange3을 통한 데이터 분석 워크숍이 진행된다. 오늘은 orange3을 활용하는 방법을 배우고, 내일은 팀별로 프로젝트를 하여 보고서를 쓰고 발표까지 하게 된다.
orange3은 개발 언어를 사용하지 않는 비주얼 프로그래밍 방식을 사용한다.
그래서 머신러닝이나 데이터 분석 단계와 기법에 대한 이해가 더 빠르게 되고, 비교적 배우기 쉽다는 장점이 있다.
[Part 1] 인공지능과 머신러닝의 이해
1. 인공지능의 7단계 발전 과정
Step1) 규칙기반 시스템
: 비즈니스 등에서 일반화된 업무 규칙 등을 사용해서 간단하고, 반복적인 업무들을 자동화 (로봇청소기, 업무용 RPA 등)
Step2) 상황인지와 유지
: 특정 분야의 우수 지식과 경험 등을 학습하고, 그들의 지식과 경험을 바탕으로 외부 상황에 대해서 반응하고 처리하는 기능들을 자동적으로 수행 (챗봇, 로봇어드바이저 등)
Step3) 특정 도메인 전문지식 활용
: 인간의 지식 처리 능력 범위를 확장하는데 도움이 되는 특정 영역에서의 전문지식의 개발과 구축을 목표
Step4) 추론하는 기계
: 인공지능 스스로가 정신 상태를 자신에게 귀속하려는 능력을 보유
Step5) 자가 인식 시스템 / 인공 일반 지능(AGI)
: 안공지능 분야의 궁극의 목표 (인간과 같은 인공지능을 개발하는 것이 목표)
Step6) 인공 초지능(ASI)
: 모든 영역에서 뛰어난 인간들의 능력을 추월하는 역량을 보유한 인공지능 개발 목표
Step7) 특이점과 초월
: 인공초지능으로 인해 가능해진 기하급수적 발전 경로가 인간 능력의 대향 확대를 가능케 하는 상황
2. 인공지능 > 머신러닝 > 딥러닝
1) 머신러닝
※머신러닝 vs 데이터 마이닝
:기계 학습은 훈련 데이터 를 통해 학습된 알려진 속성을 기반으로 예측에 초점을 맞추고, 데이터 마이닝은 데이터의 몰랐던 현상이나 특징을 발견하는 것에 집중한다.
2) 머신러닝의 유형
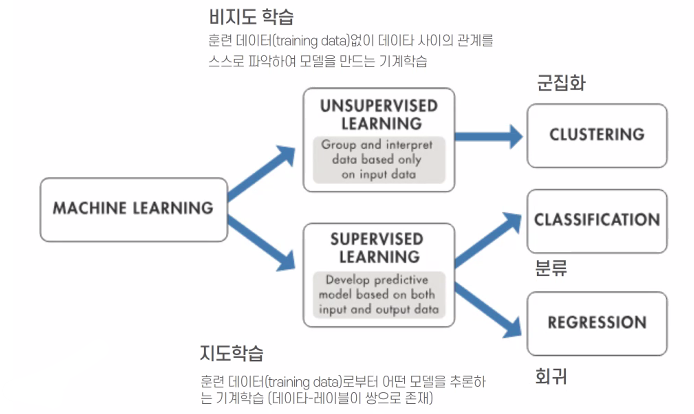
· 비지도 학습: 군집화, 계층적 군집화
· 지도 학습: 분류, 회귀/예측
· 강화 학습(Reinforcement Learning): 에이전트와 보상을 통해 인공지능 훈련 ex) 알파고
3) 기계 학습의 어려움: 편향과 분산
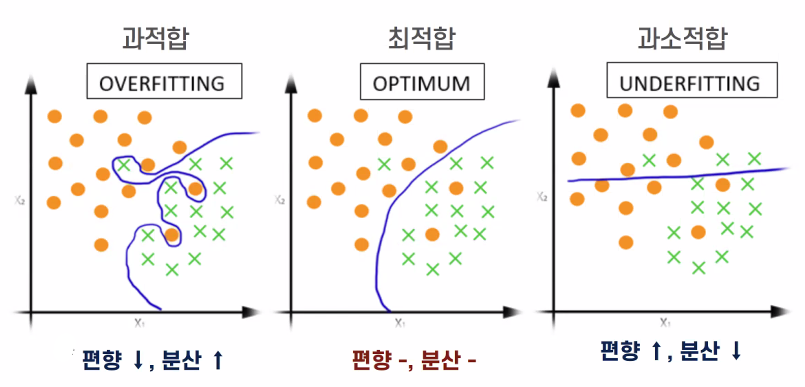
과적합도 안되고, 과소적합도 안되고, 최적합을 찾아야 한다.
4) 딥러닝 (DNN, Deep Neural Network)
: 데이터를 보다 심층적으로 이해하고 처리하기 위해서 개발된 학습 방식
- '퍼셉트론'의 이해
: 인간의 신경세포인 뉴런을 모방한 기계학습을 위한 알고리즘인 신경회로망(ANN, Artificial Neural Network)의 문제를 사전학습을 통해 다수 해결하면서 딥러닝이 나타났다. 기존의 ANN의 경우, 계층이 많아지면서 계산량 증가 및 가중치에 대한 학습이 잘 되지 않는 문제점이 발생하기 때문이다.
ex) 이미지 분류, 얼굴인식, 차원 압축, 이미지 생성, 음성인식과 합성
- 한계와 위험
- 테이터가 없으면 모델 학습이 어려움
- 잘못된 예측에 대한 책임
- 기계학습의 모델에 예측결과 변경과 해킹
- 학습 모델 복제 또는 사용된 데이터 유출
※ 차원이란?
학습 데이터는 다양한 차원을 가진다. 1차원(시간), 2차원(넓이와 높이), 3차원(넓이, 높이, 시간) 등. 차원이 클수록 구제적으로 설명이 가능해진다. 그러나 모든 차원에 충분한 데이터를 모으기 어렵기 때문에, 학습모델의 성능이 떨어질 수 있다. 꼭 차원이 많다고 좋은 것은 아님!
[Part 2] Orange3 처음 사용해 보기
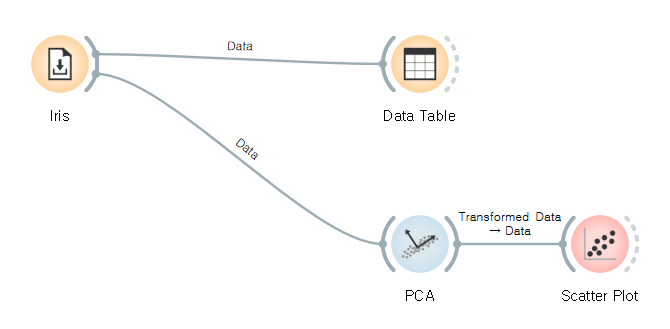
Dataset > 'Iris': 붓꽃 데이터셋 (붓꽃의 3가지 유형, 꽃받침과 꽃잎의 너비와 길이)
1. 다양한 위젯을 드래그를 통해 링크로 연결하기
참고로 연결은 왼쪽이 입력, 오른쪽이 출력이다.
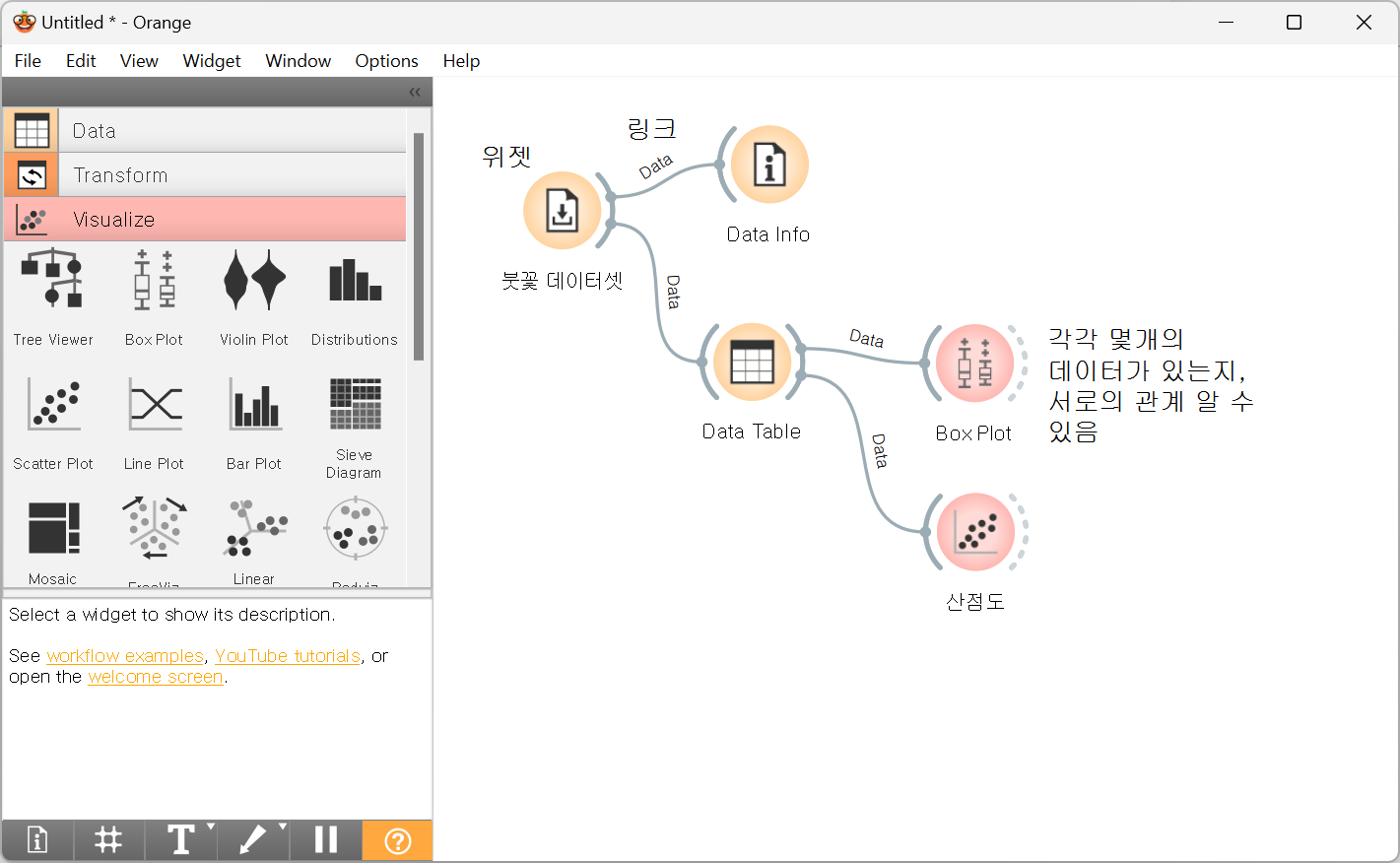
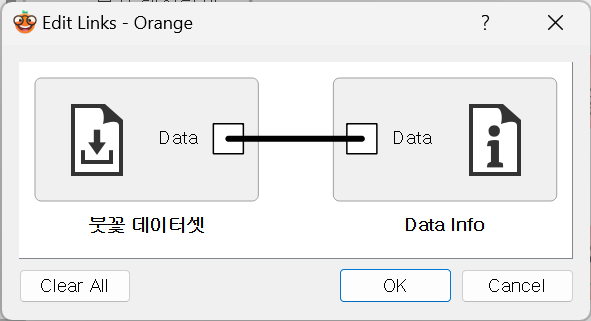
2. 링크를 더블클릭하면 왼쪽은 입력, 오른쪽은 출력 설정 (Data → Data)
- Data Table
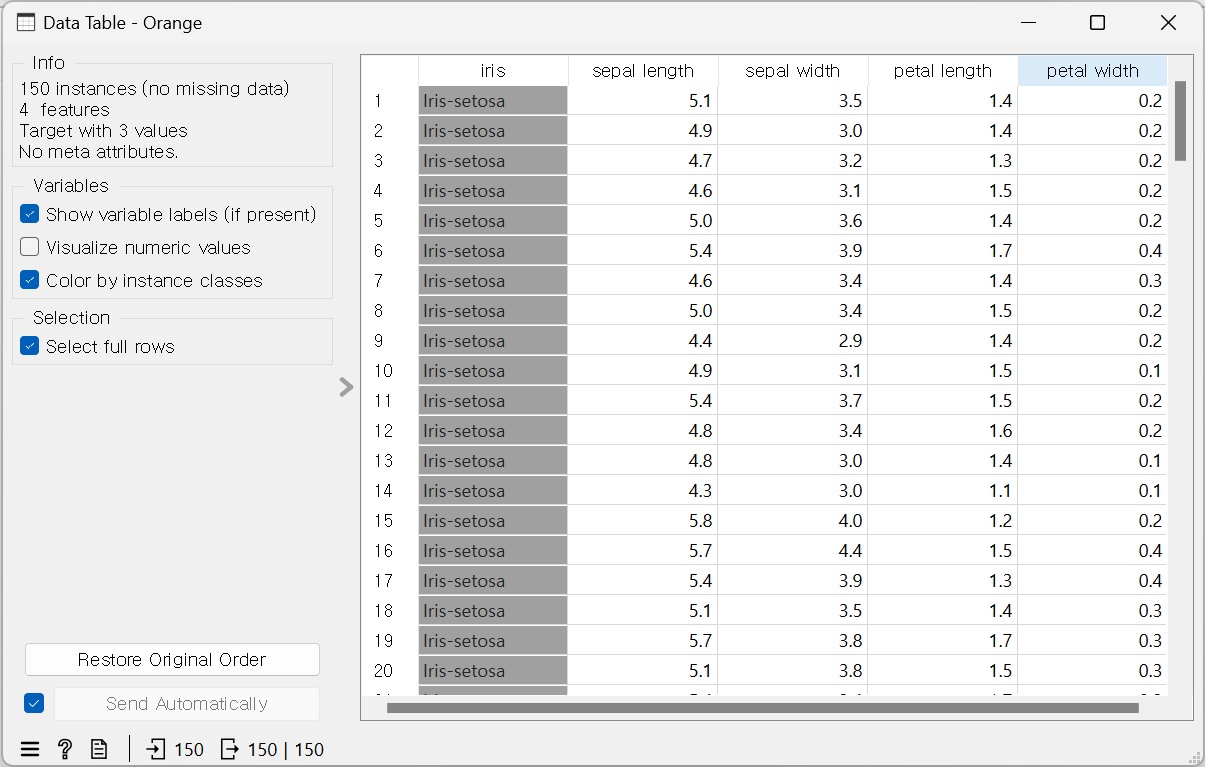
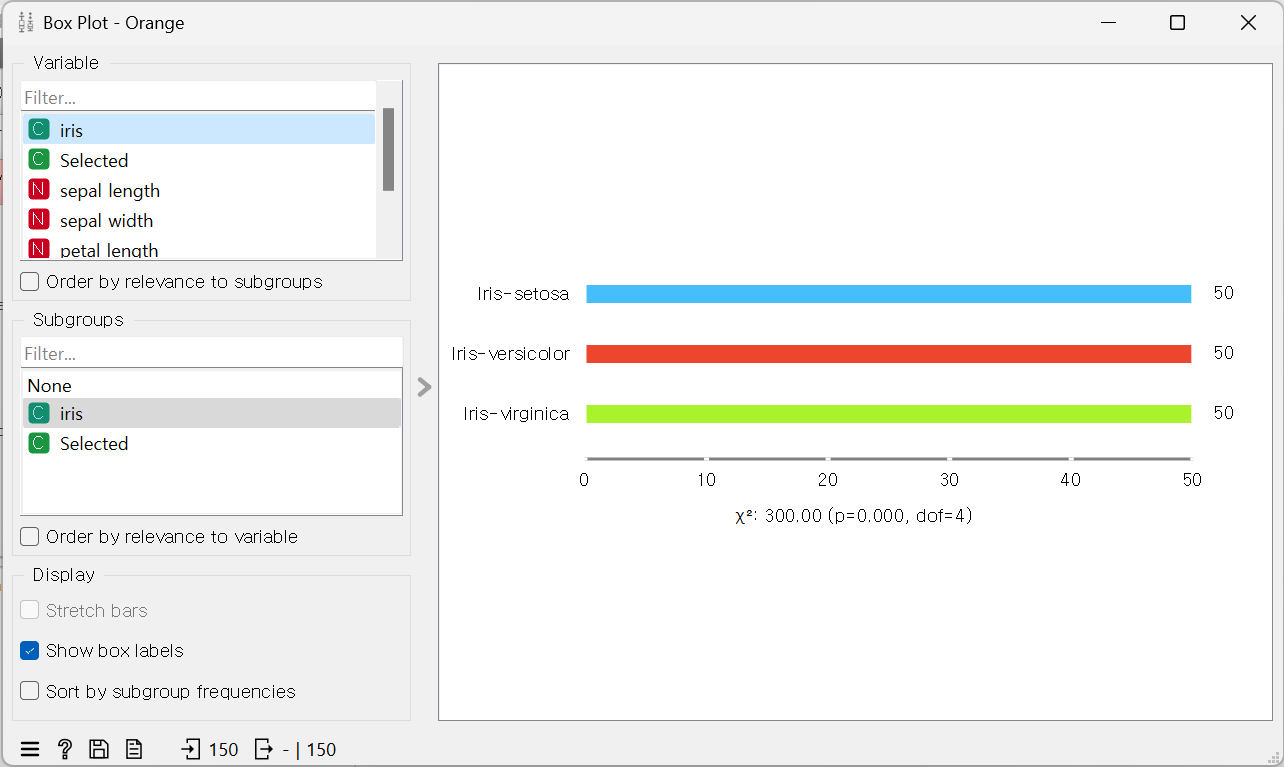
- Box Plot
: 각각 몇 개의 데이터가 있는지, 연관성 등 확인
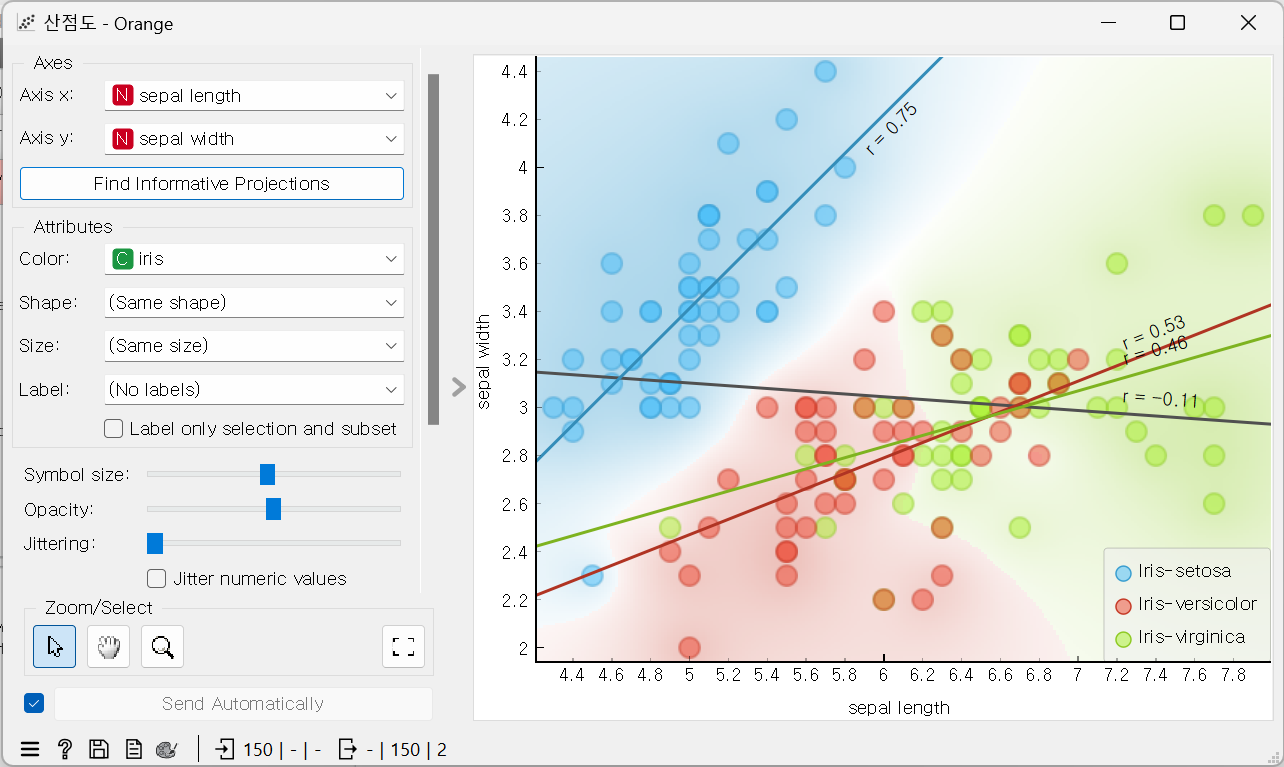
- Scatter Plot(산점도)
- x, y축 설정도 가능
- show regression line: 회귀선
[Part 3] Orange3으로 기술통계 보기
1. Feaure Statisitcs (기술 통계값): 평균값, 중앙값 등
Dataset: 'Housing' (보스턴 주택 가격)
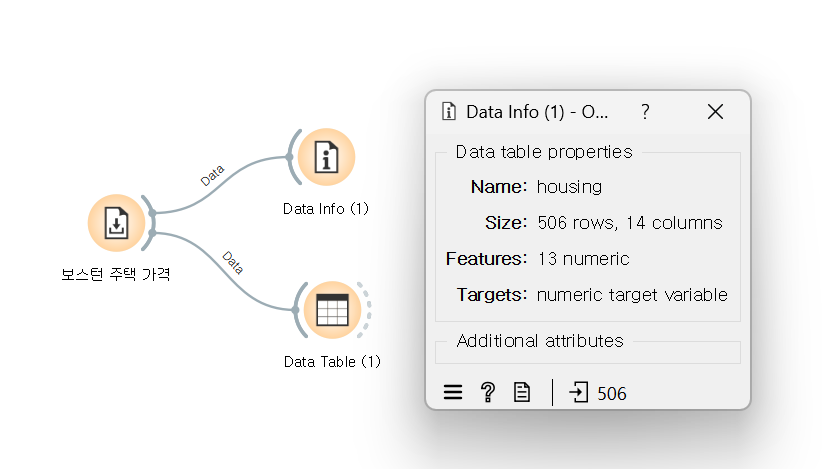
· missing: 비어 있는 데이터 수
· 첨도나 왜도는 없음
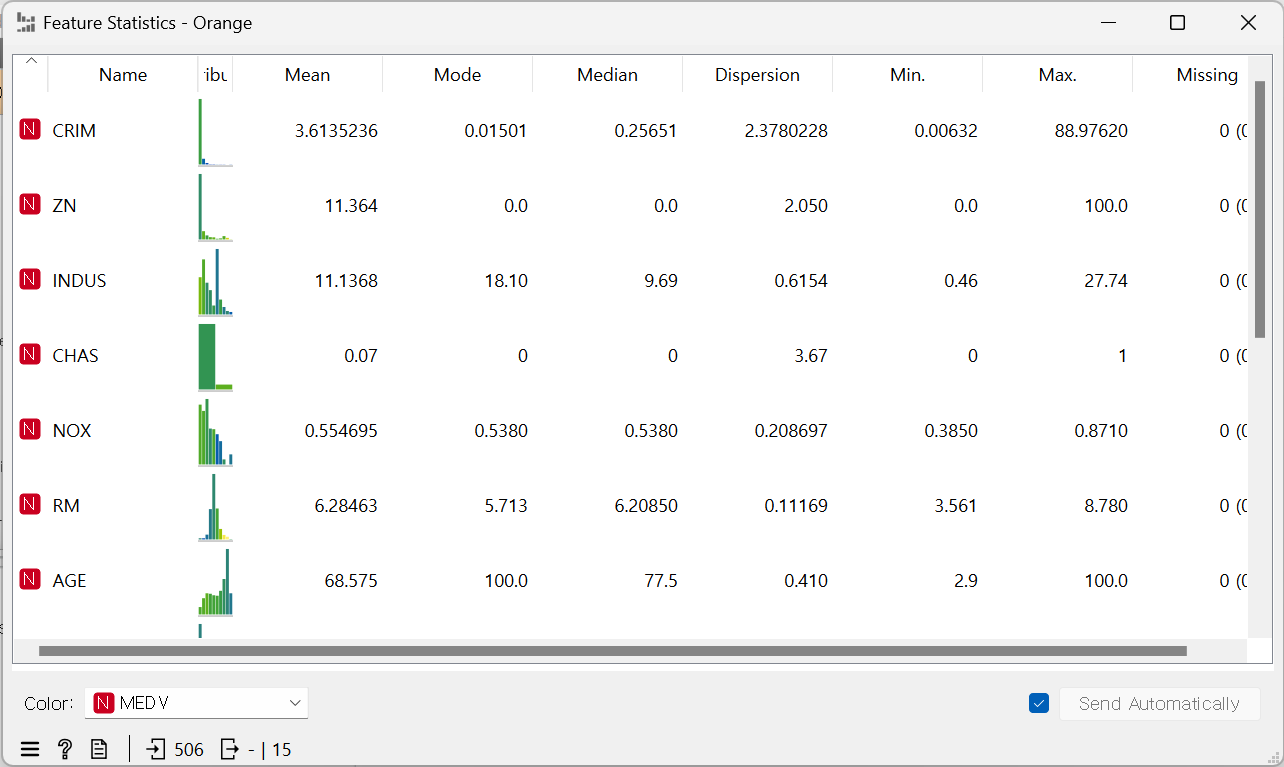
2. 왜도와 첨도 추가
: orange3에서 기본으로 제공하는 건 없기 때문에 코드로 추가
우선, 기술통계표를 추가하기 위해 Transform > Python Script 들어가서 아래의 새로운 코드 추가 → 실행(Run)
import Orange
from Orange.data.pandas_compat import table_from_frame
from Orange.data.pandas_compat import table_to_frame
import pandas as pd
df = table_to_frame(in_data)
desc = df.describe()
out_data = table_from_frame(desc)여기에 Data Table 연결 → 추가된 것 확인
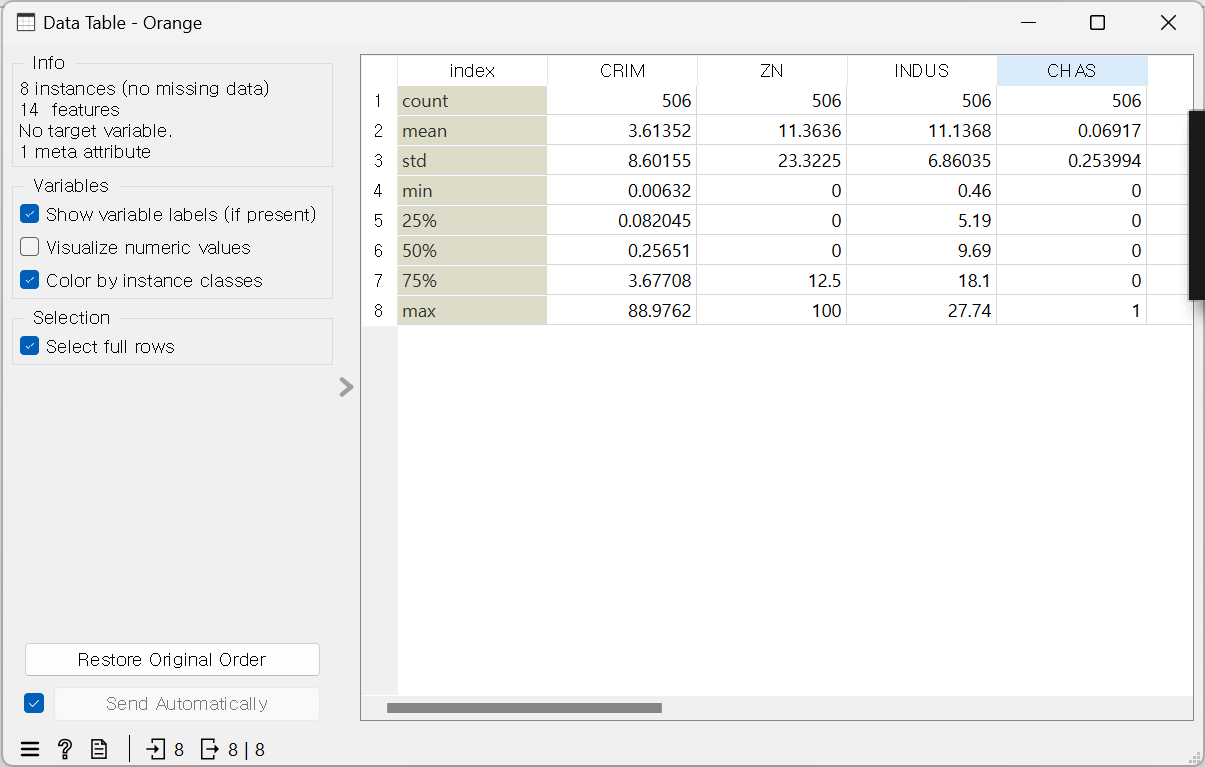
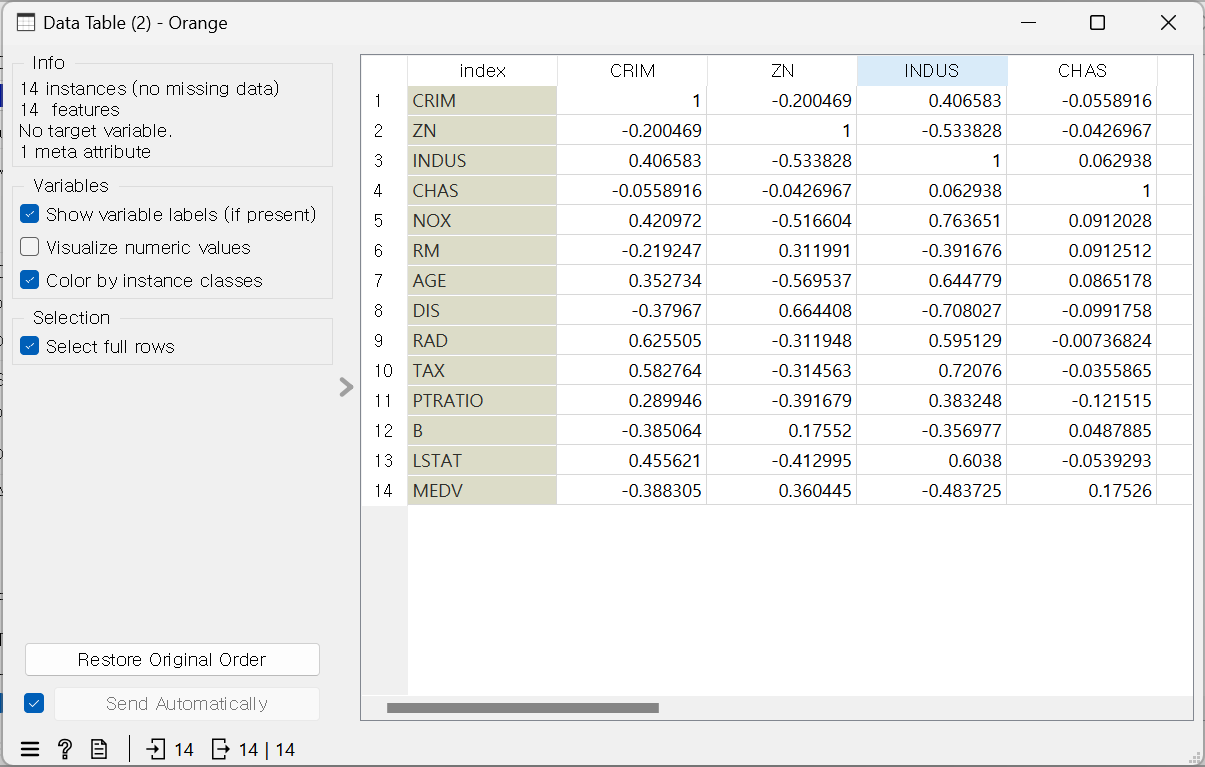
3. 차원 간 상관계수
: 두 개의 변수 간의 연관관계의 강도를 표시 (-1 ~ +1)
· 데이터 간의 속성 파악 가능
· 상관관계가 클수록 1에 가까움
· 위젯: Unrelated > Correlations
- LSTAT: 모집단의 하위 계층
- RM: 방의 개수
- MEDV: 가격
ex) MEDV와 RM: 양의 상관계수, 한쪽이 늘어나면 다른 한쪽도 늘어난다는 의미
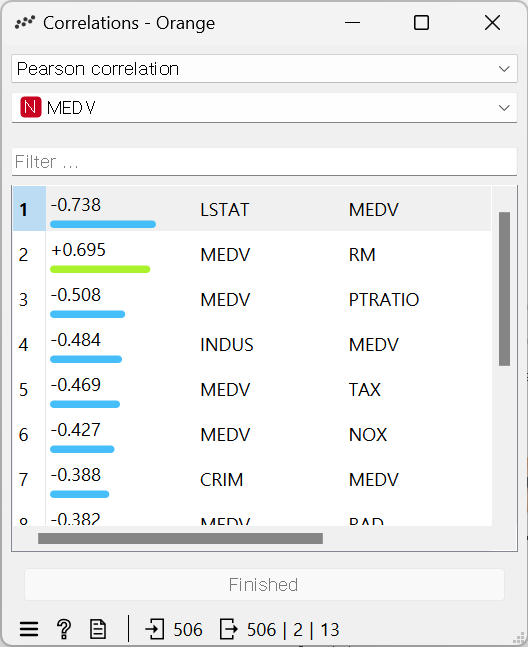
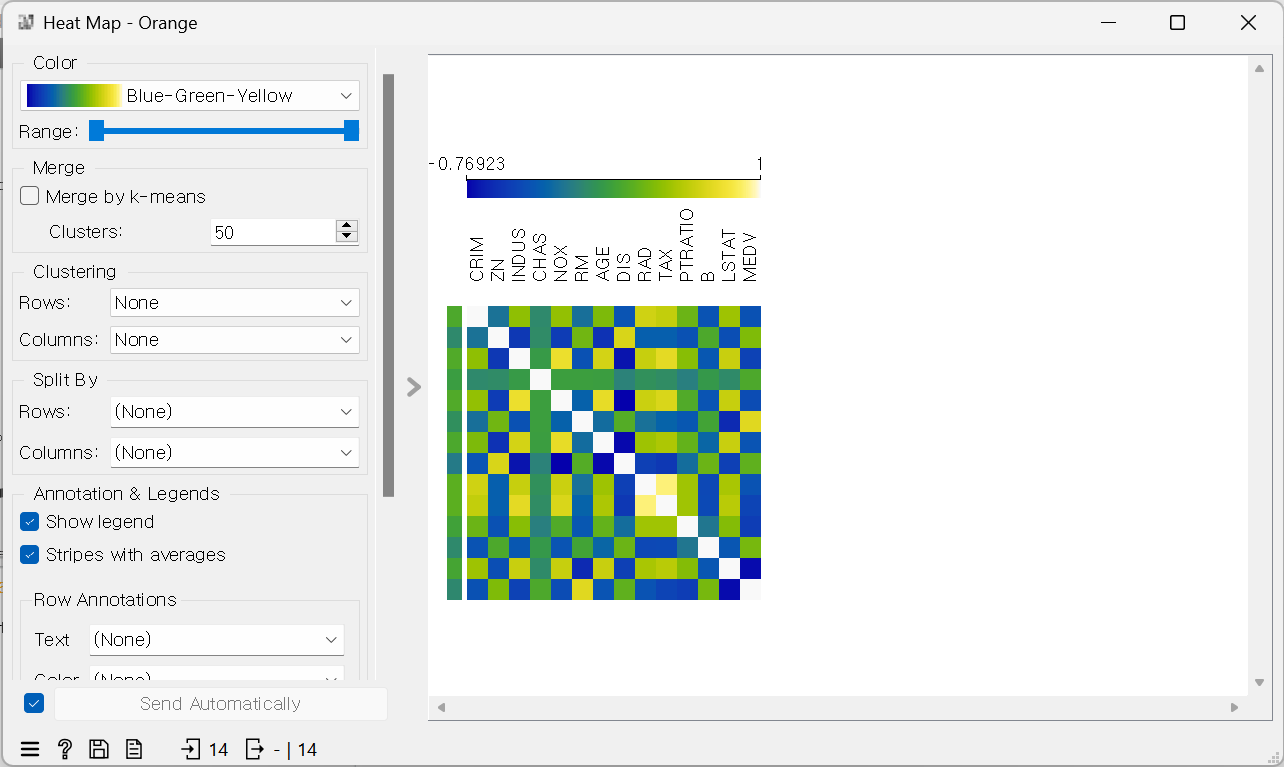
- 상관계수 매트릭스 계산하고, heatmap으로 시각화하기
파이썬 코드 추가
import Orange
from Orange.data.pandas_compat import table_from_frame
from Orange.data.pandas_compat import table_to_frame
import pandas as pd
df = table_to_frame(in_data)
#상관계수 구하기
corr = df.corr()
out_data = table_from_frame(corr)상관계수 data table 연결
Heatmap 연결
[Part 4] 특징값 정제와 반환
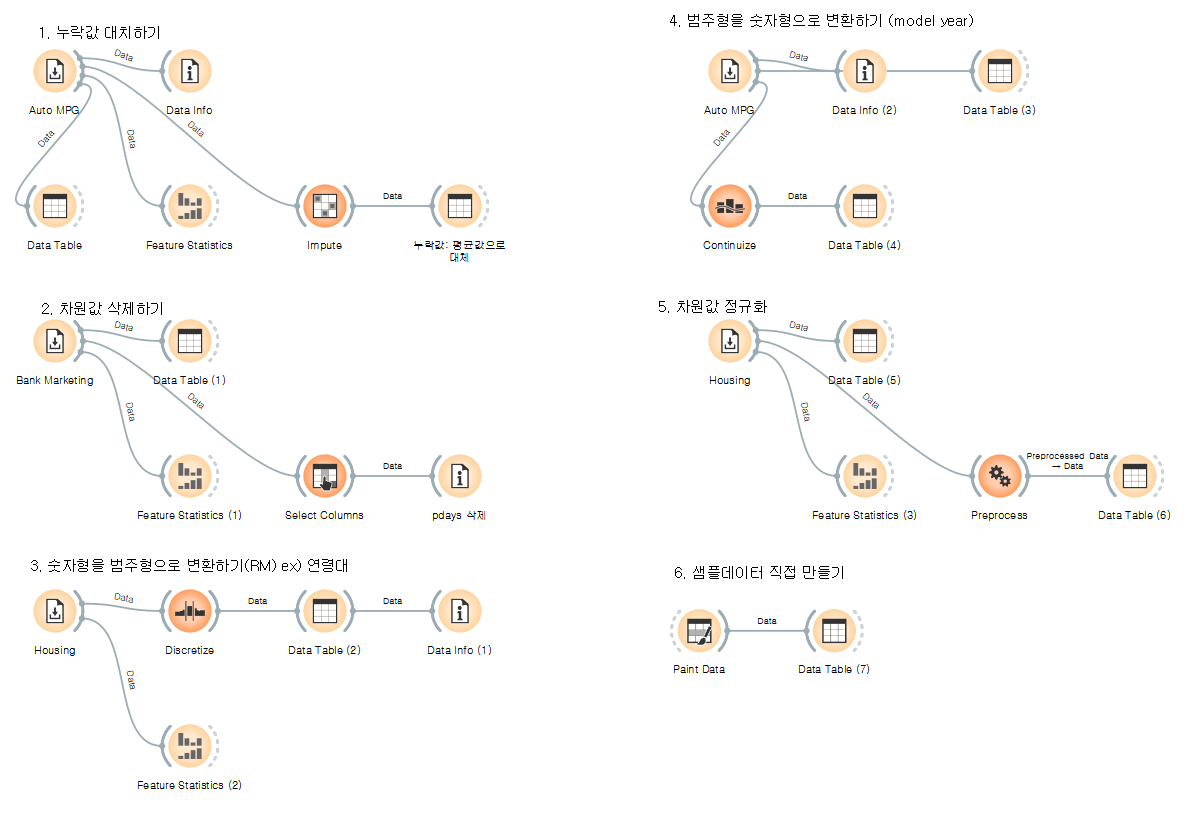
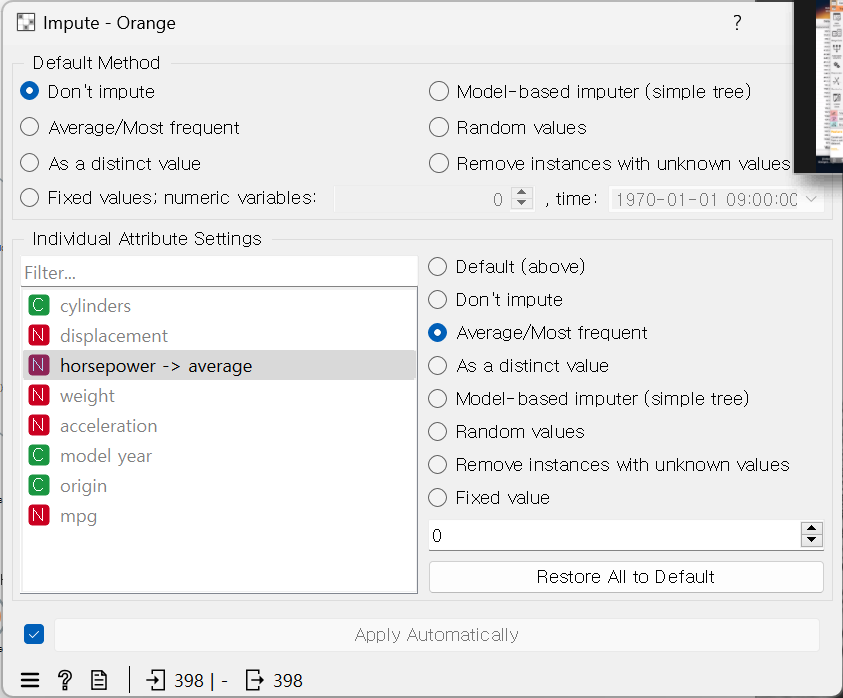
1. 데이터의 누락값을 평균값으로 대치하기
Data Set: 'Auto MPG'
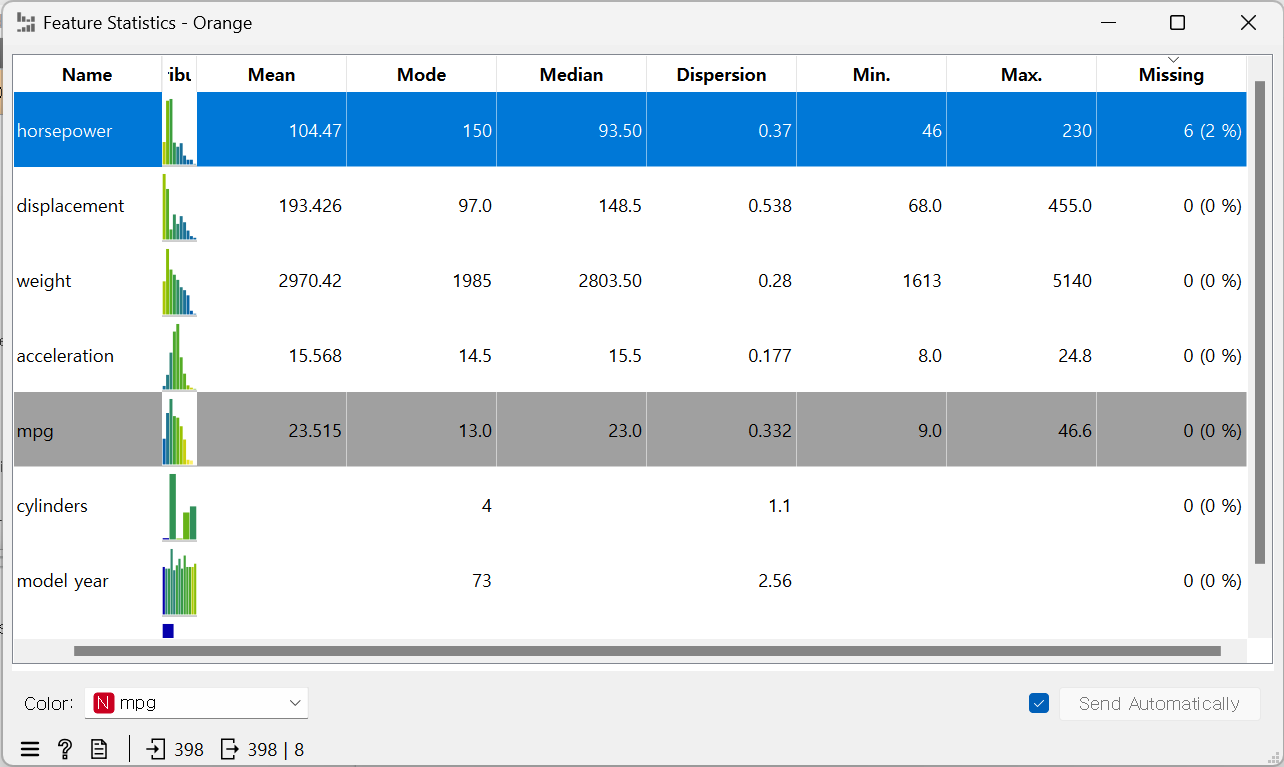
- Imput > 'horsepower -> Average'
2. 차원 값 삭제하기
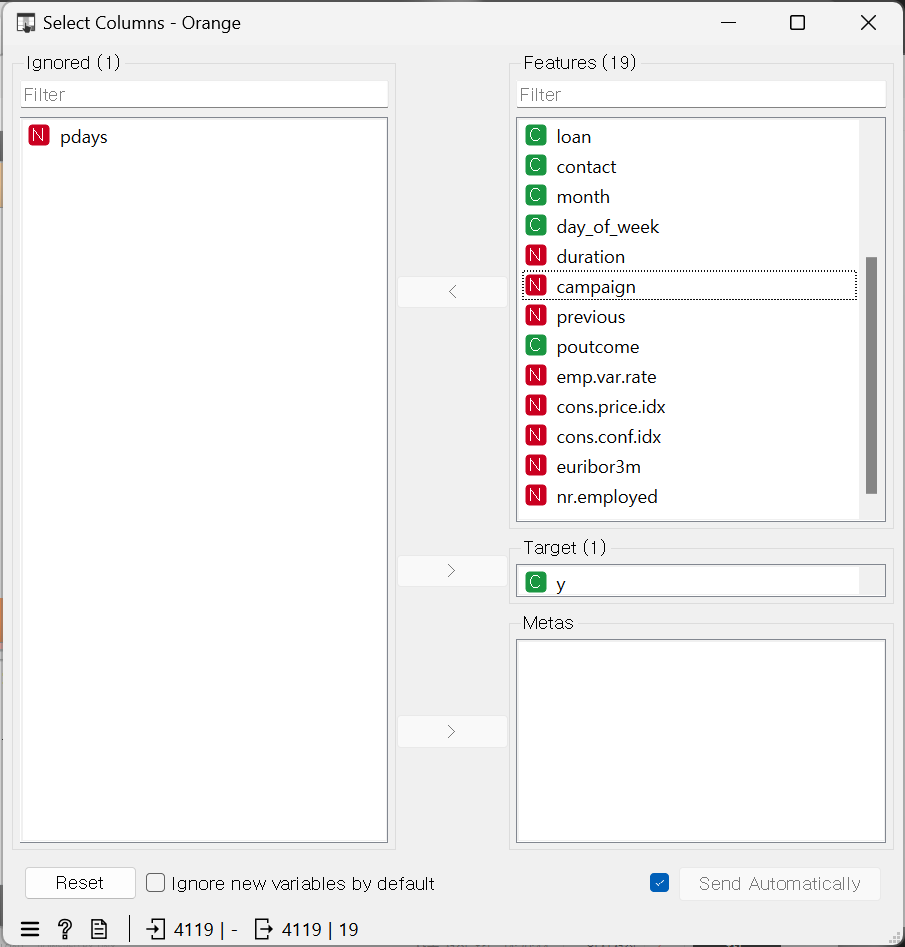
Data Set: 'Bank Marketing'
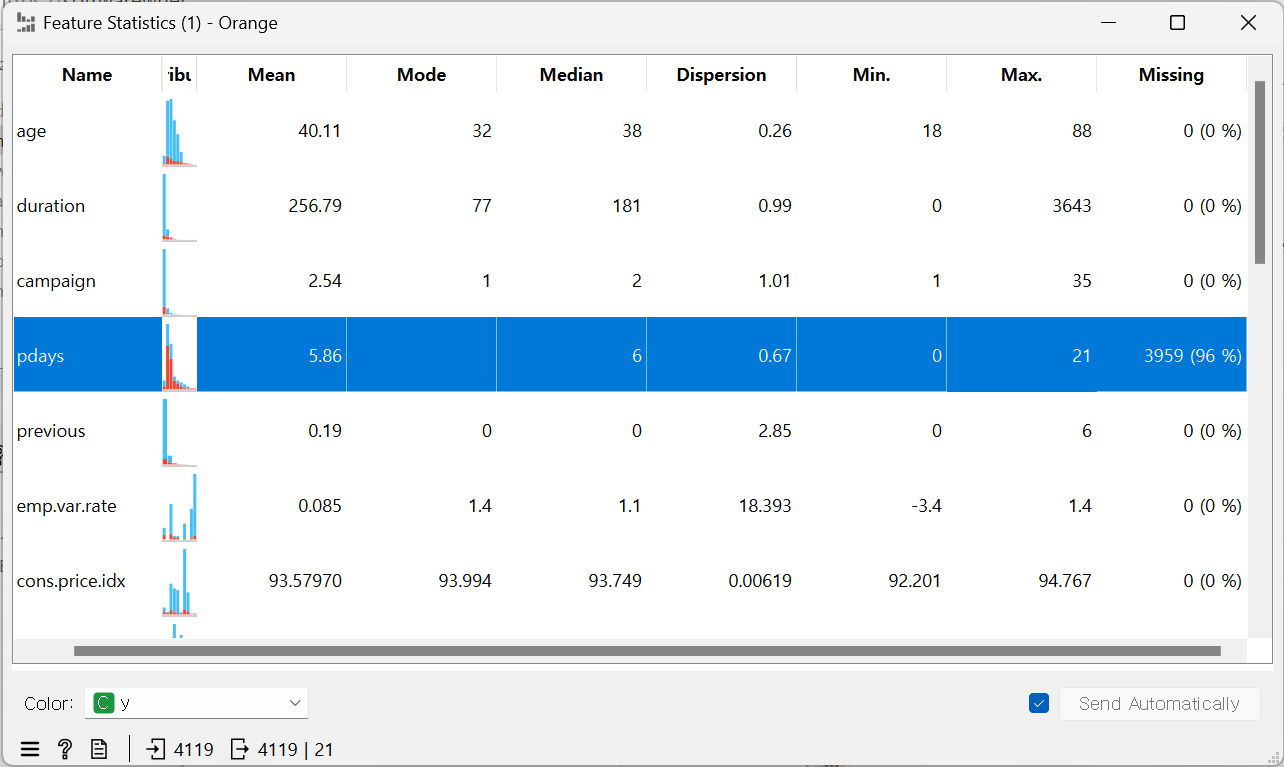
pdays의 누락값 96%라서 아예 삭제해 주기: Select Columns > pdays를 Ignored에 옮기기
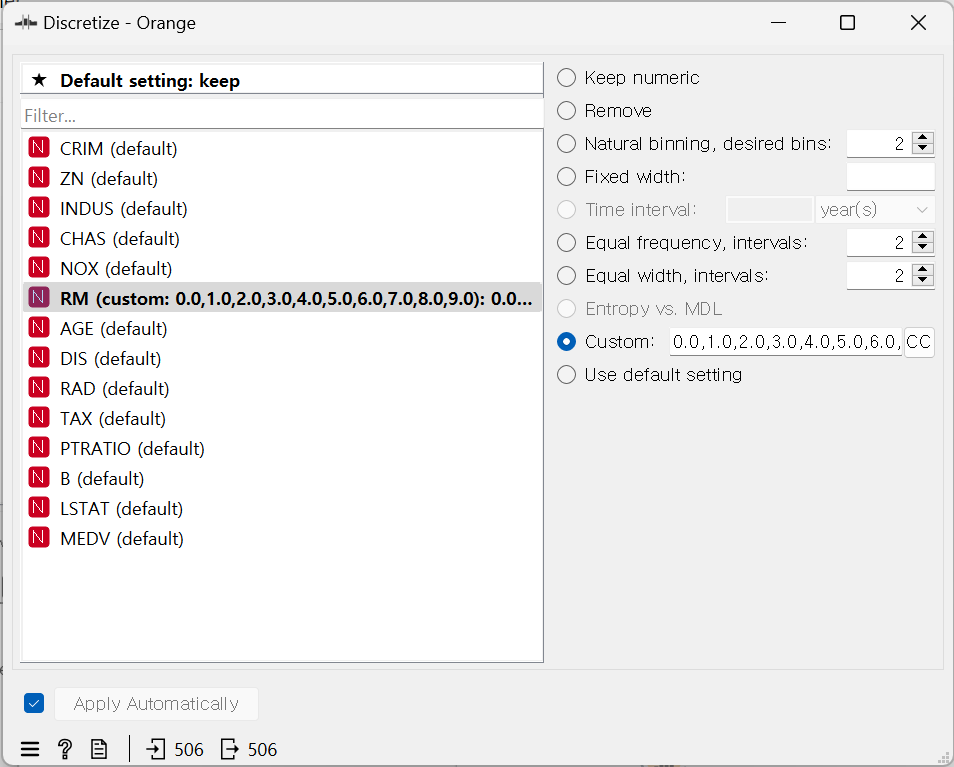
3. 숫자형을 범주형으로 변환하기 ex) 연령
Data Set: 'Housing'
RM 항목을 변환할 것이다. → Discretize
4. 범주형을 숫자형으로 변환하기
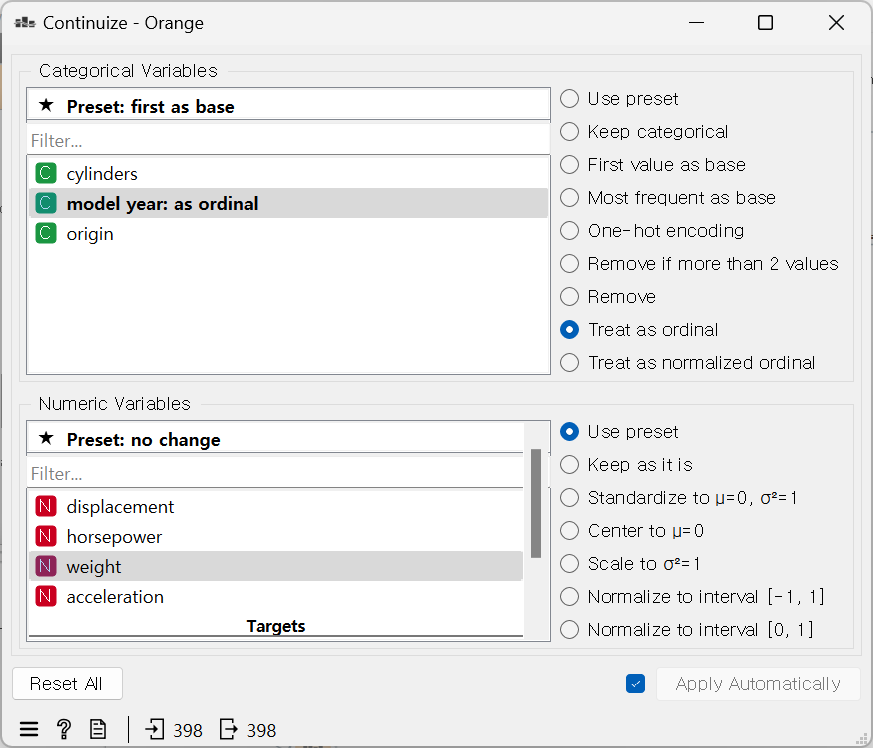
model year 항목을 변환 → Continuize > model year > Treat as ordinal
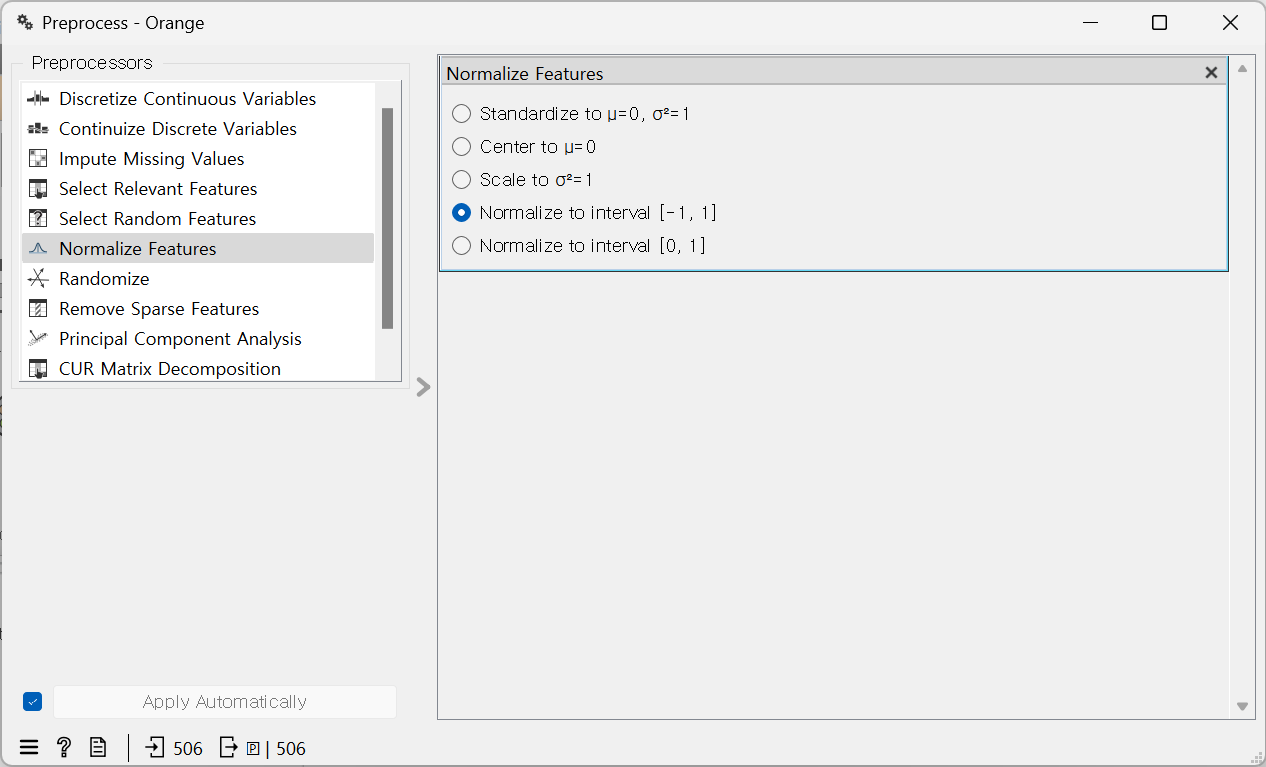
5. 차원값 정규화하기
Data Set: 'Housing'
- Preprocess(전처리) > Normalize Features
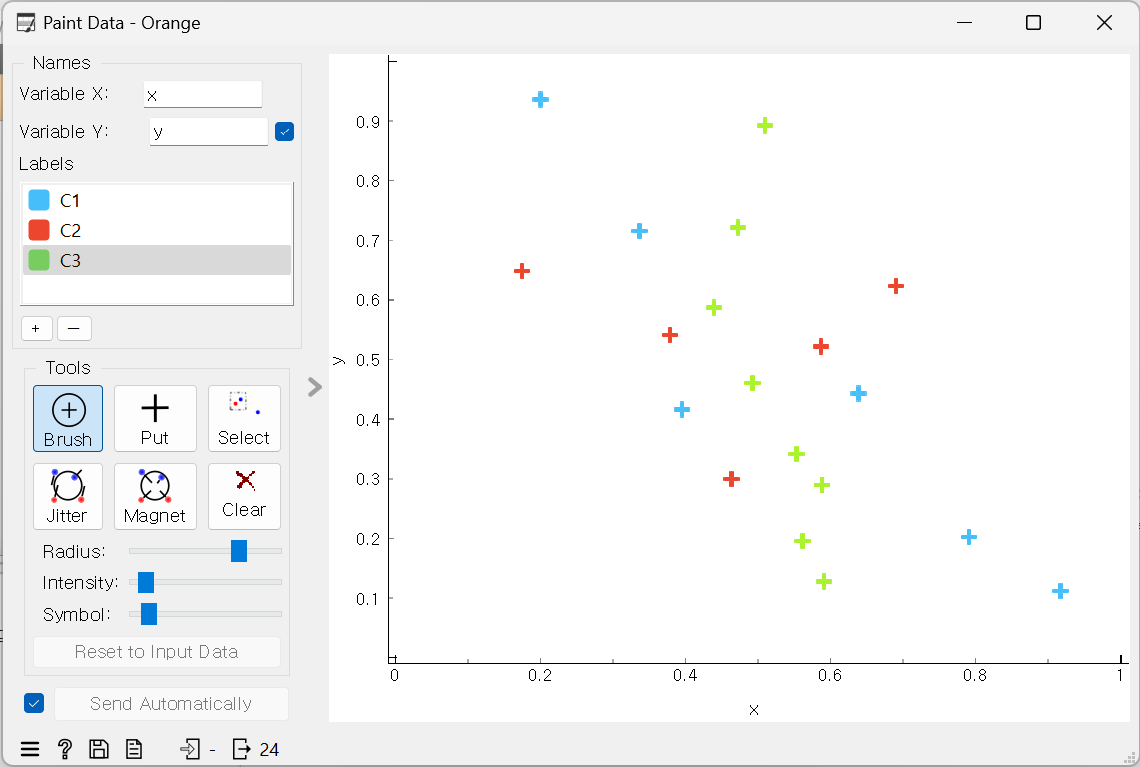
6. 샘플 데이터 만들기
- Paint Data
[Part 5] 성능을 높이는 특징 선택과 추출
1. 차원 축소
1) 특징 추출
: 기존 특징들의 차원을 줄여서 저차원의 특징으로 변환 (20차원 -> 10차원)
- 변환된 값을 기존 특징값과 완전하게 다르며, 기존값으로 복원 불가
2) 특징 선택
: 기존 특징에서 불필요한 특징을 제거하거나 분별이나 예측에 도움 되는 특징만 남김
- 선택된 특징값은 차원이 줄어도 그대로 원래의 값을 유지
2. 주성분 분석 (PCA, Principle Component Analysis)
: 데이터의 차원들을 고차원에서 저차원으로 변환하는 대표적인 특징 추출 방법
※ 해당 카테고리는 딥노이드, 오픈놀, 앙트비에서 주최하는 '<스타트업 유니버시티: DX Challenge 교육> AI+X 역량 강화 트랙'에 대한 기록입니다.
'[AI+X 역량 강화] 인공지능 > 3) 실전 챌린지: 스마트 트랜스폼' 카테고리의 다른 글
| 인공지능을 활용한 자율비행 드론 프로그래밍 // Tello Drone (0) | 2023.09.23 |
|---|---|
| 컴퓨터비전을 활용한 자율자동차 AI 프로그래밍#2 // 동키카 데이터 수집 방법 (0) | 2023.09.17 |
| 컴퓨터비전을 활용한 자율자동차 AI 프로그래밍#1 // 동키카로 데이터 수집, 처리, 저장, 학습 (0) | 2023.09.16 |
| 데이터 분석 워크숍(orange3 활용)#3 // 군집화, 앙상블 학습, 팀프로젝트 (0) | 2023.09.10 |
| 데이터 분석 워크숍(orange3 활용)#2 // 분류, 알고리즘, 회귀, 예측 (0) | 2023.09.09 |



