오늘은 주특기 과정 중에서도 머신러닝의 첫수업이다.
머신러닝에 대한 전체적인 개념과 이론에 대해 배운다.
1. 머신러닝의 개념
지능은 본능적이나 자동적으로 행동하는 대신에 생각하고 이해하여 행동하는 능력을 말한다. 즉, 인공지능에 접해봤을 때는 어떤 문제가 주어졌을 때, 합리적으로 사고하여 문제를 해결하는 능력이다.
머신러닝은 직역하면 '학습하는 기계'이다. 학습이란 반복적인 경험을 토대로 미지의 문제를 추론하고 틀린 것은 다시 연습하는 것이다. 예를 들어, 아기는 무엇이든 입어 넣어본다. 그러나 다양한 경험을 하면서 뽀죡하고 딱딱한 것은 입에 넣었을 때 아프기에 해서는 안되고, 달콤한 것은 맛있다는 사실 등을 깨닫게 된다. 그리고 이러한 학습을 기반으로 경험하지 않은 것도 판단이 가능하다. 초콜릿을 먹어본 아이는 초코케이크를 먹어보지 않아도 비슷한 향과 생김새로 맛있다는 것을 유추할 수 있는 것처럼 말이다.
즉, 사람은 새로운 경험을 바탕으로 학습하면서 더 높은 수준의 인지력을 갖게 된다. 머신러닝은 이처럼 새로운 데이터를 바탕으로 학습하면서 더 정교한 추론이 가능해지고, 데이터가 바뀌어도 스스로 지속 발전이 가능하다.
※기계 학습: 컴퓨터를 인간처럼 학습하게 하여 스스로 새로운 규칙을 발견할 수 있도록 하는 알고리즘이나 기술
2. 머신러닝의 과정

① 빅데이터 입력
② 데이터 분석하여 모델 학습
③ 의사 결정 및 예측을 위한 실제 데이터
④ 모델을 이용하여 의사 결정 및 예측 등 수행
⑤ 피드백을 통해 모델 성능 개선
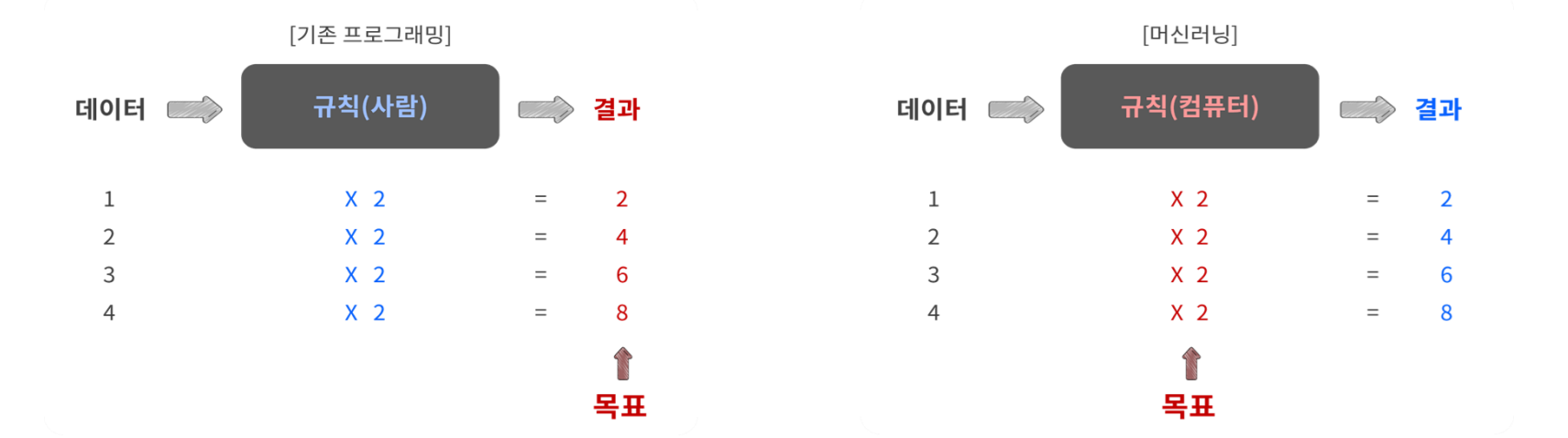
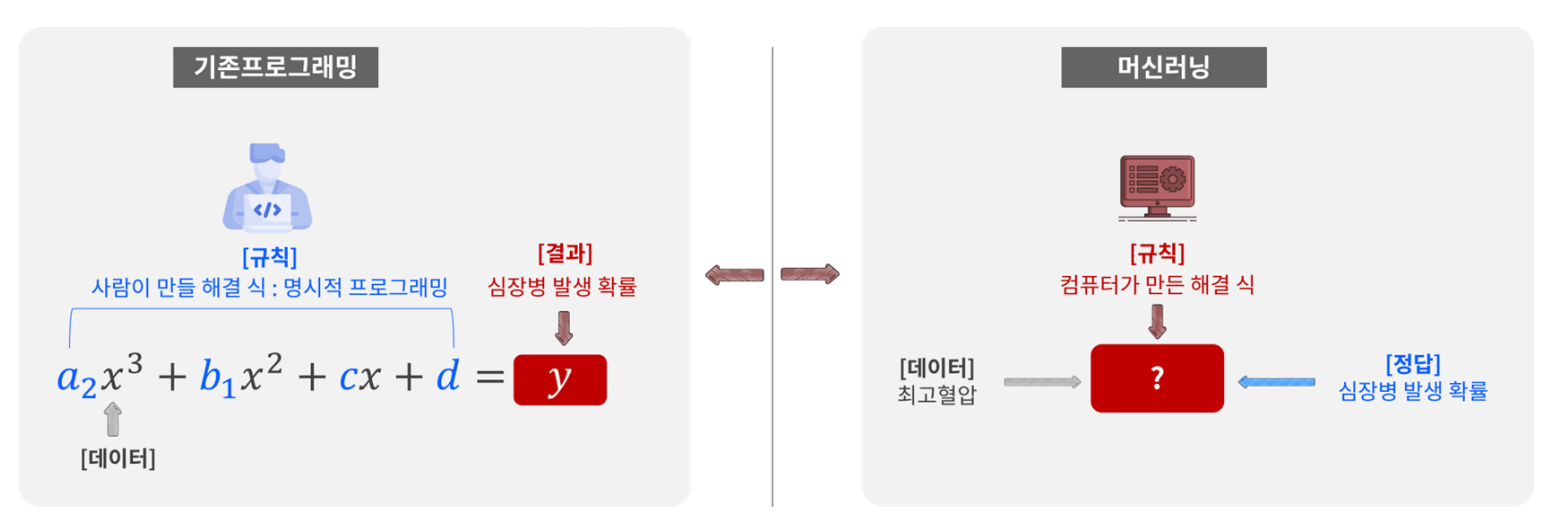
3. 기존 프로그래밍과 머신러닝의 차이
- 기존 프로그래밍: 데이터 + 규칙 → 출력 생성
- 머신러닝: 데이터 + 출력 → 규칙 생성
4. 머신러닝의 특징
- 새로운 문제가 발생하면, 컴퓨터가 알아서 규칙을 찾는다
- 시간이 지날수록 컴퓨터는 문제를 더 잘 해결한다 (데이터가 많아지기 때문)
- 규칙과 데이터가 바뀌는 상황도 알아서 해결한다
결국, 사람이 하는 번거로운 작업을 감소시키고 어려운 문제를 사람보다 더 잘 푼다.
▶ 기계가 학습한다는 것은 데이터와 정답을 축적하면서 문제를 해결하는 규칙을 계속 변경해 가는 것이다.
5. 스팸 필터
: 스팸 메일과 일반 메일의 샘플을 이용하여 스팸 메일 구분법을 배운 첫번째 머신러닝 애플리케이션
- 훈련 세트: 시스템이 학습하는데 사용하는 샘플
- 정확도: 정확히 분류된 샘플의 비율
- 기존프로그래밍 기법으로 스팸 필터 생성
1) 스팸 메일에 주로 나타나는 단어 확인 → 패턴 분석
2) 패턴을 감지하는 알고리즘 작성 → 해당 패턴에 대응하여 스팸으로 분류
3) 성능이 나올 때까지 무한 반복
▷ 규칙이 점점 길고 복잡해져서 유지 보수가 힘들어진다는 단점
- 머신러닝으로 스팸 필터 생성
1) 스팸에 자주 나타나는 단어를 감지어 분류하는 좋은 기준을 가동으로 학습
▷ 한단계가 끝!

6. 머신러닝의 종류
- 사람이 반복적으로 업뮤를 하거나 위험한 업무를 대신하는 경우
- 사람이 일아기 위험한 환경에서 일을 수행하는 경우
- 특정 범최인을 찾거나 추억
- 촬영 장소에 불이 나거나 이상한 상황을 발견
- 총기를 들고 있는 사람 발견
- 사람이 직관적으로 판단하기 어렵거나 빠르게 처리해야하는 경우
- 날씨 예측
- 개인 맞춤형 추천
- 키워드 기반 또는 자동 추천 (유튜브, 넷플릭스)
- 검색을 통한 추천
7. 데이터의 종류
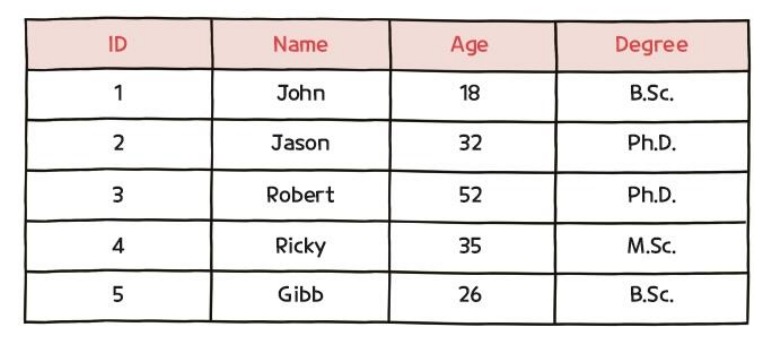
1) 정형 데이터 (Structured Data)
- 일정한 형식이나 규칙에 맞게 저장된 데이터
- ex) 스프레드시트, 관계형 데이터베이스, CSV
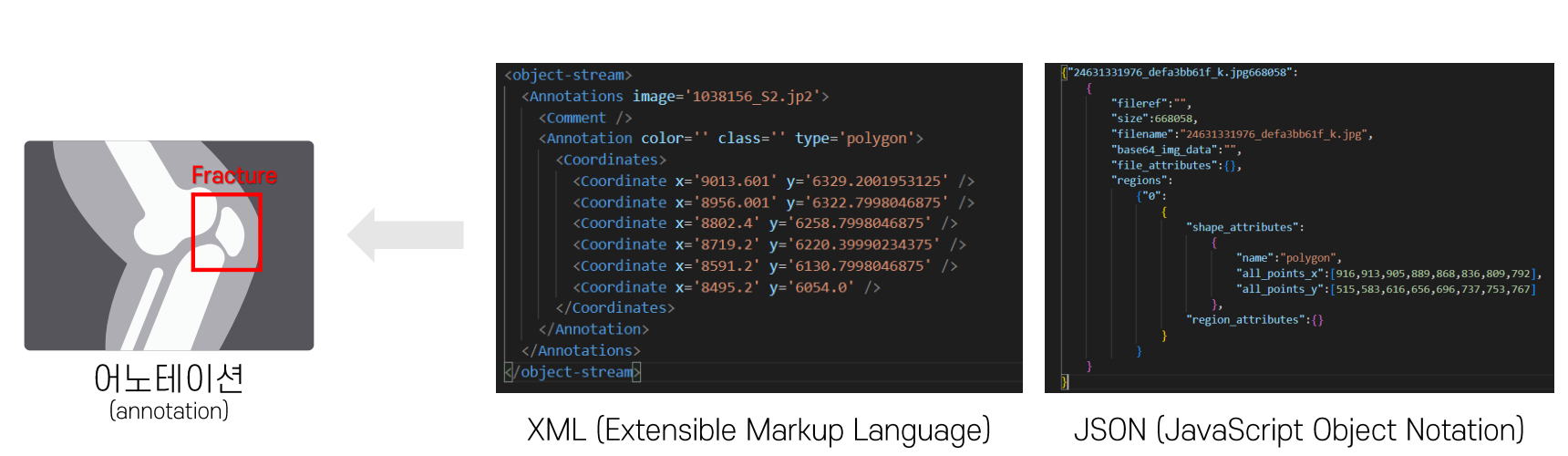
2) 반정형 데이터 (Semi-structured Data)
- 정형 데이터와 같이 테이블의 구조(행, 열)로 이루어져 있지 않음
- 별도의 태그나 마커로 요소들을 구분
- ex) XML, JSON
3) 비정형 데이터 (Unstructured Data)
- 정해진 규칙이 없는 데이터로, 값의 의미를 쉽게 파악하기 힘든 경우가 많음
- 비정형 데이터로부터 인사이트를 얻는 사례가 많아지면서 중요성 부각
- ex) 영상, 이미지, 음성, 텍스트
※ 해당 카테고리는 딥노이드, 오픈놀, 앙트비에서 주최하는 '<스타트업 유니버시티: DX Challenge 교육> AI+X 역량 강화 트랙'에 대한 기록입니다.
'[AI+X 역량 강화] 인공지능 > 2) 주특기 심화: 머신러닝, 딥러닝' 카테고리의 다른 글
| 딥러닝 활용 프로젝트 // 나이 예측앱, 백혈병 분류앱 만들기 (0) | 2023.09.20 |
|---|---|
| [머신러닝] #3 정형데이터 전처리 실습 // 결측치 처리(평균, 최빈값), 정규화, missingno (1) | 2023.09.16 |
| [머신러닝] #2 머신러닝을 위한 데이터 전처리 // 특성공학, 결측값, 범주형 변수 처리 (0) | 2023.09.09 |
| DX AI 산업 특강 // 챗GPT로 웹페이지 만들기 (0) | 2023.09.07 |


